Vivado工程文件如图:
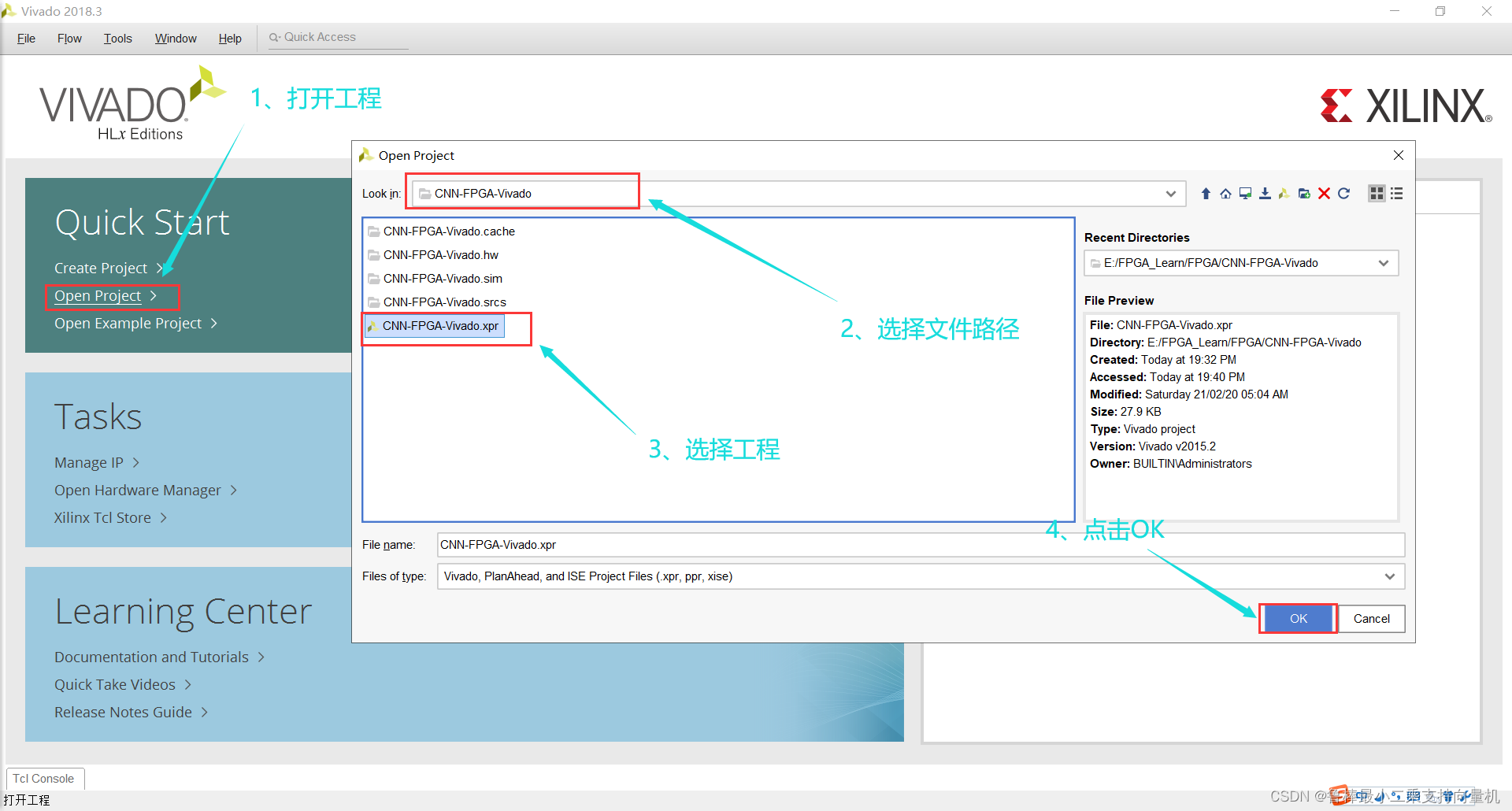
打开Vivado软件,打开工程,如图:
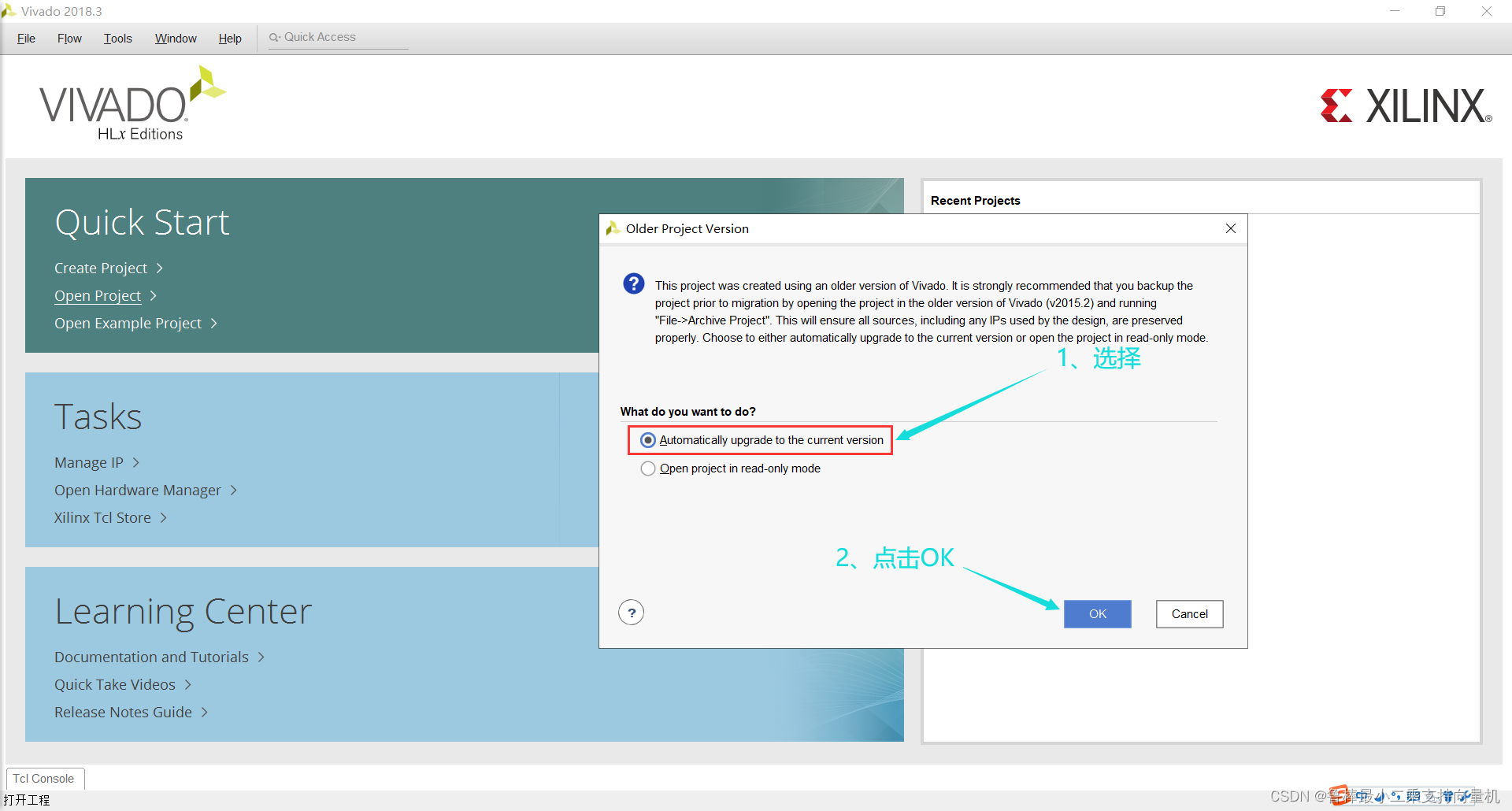
自动升级到当前版本,如图:
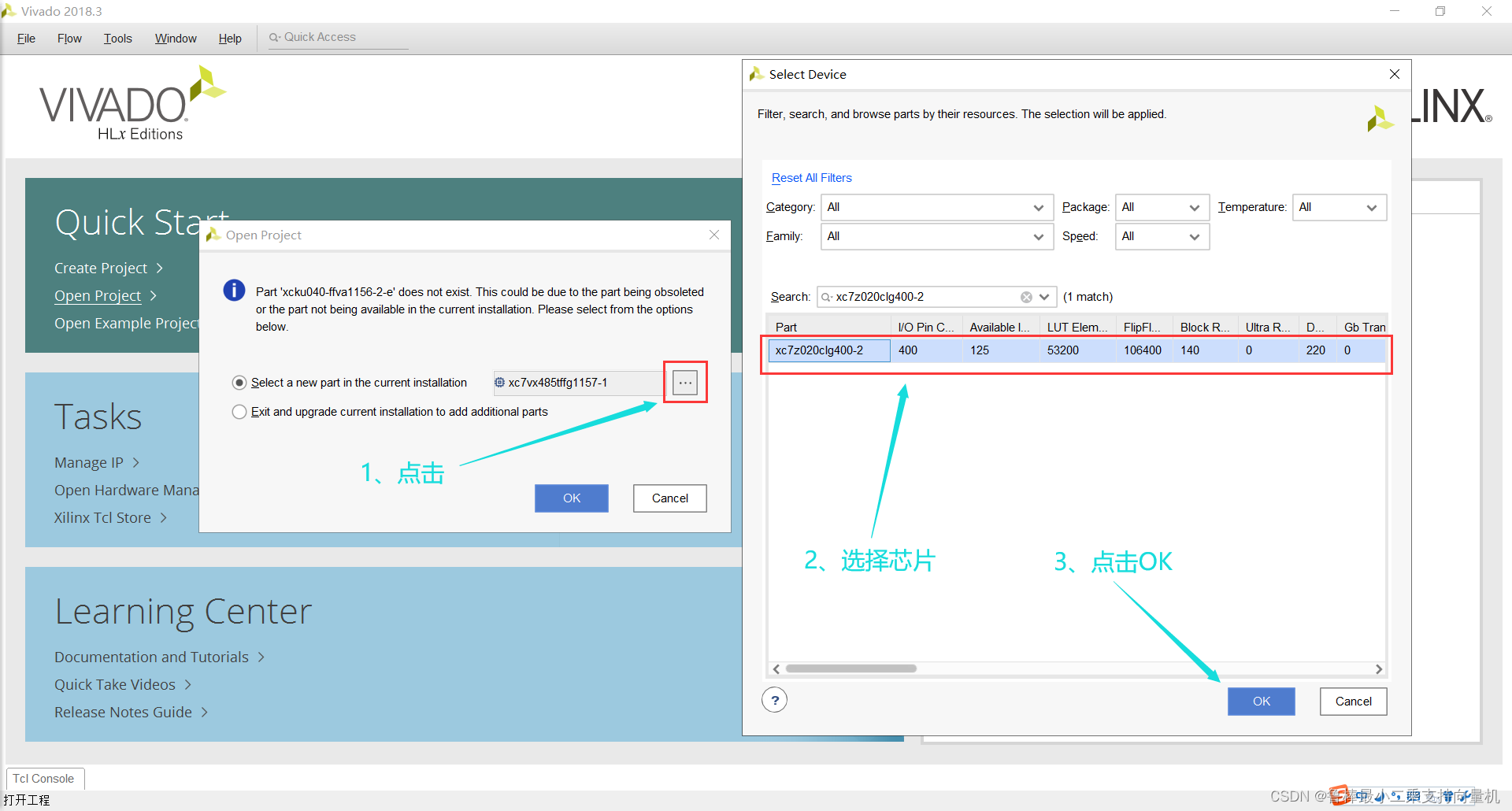
暂时选择现有开发板的型号,如图:
出现一条警告性信息,暂时先不管,点击OK:
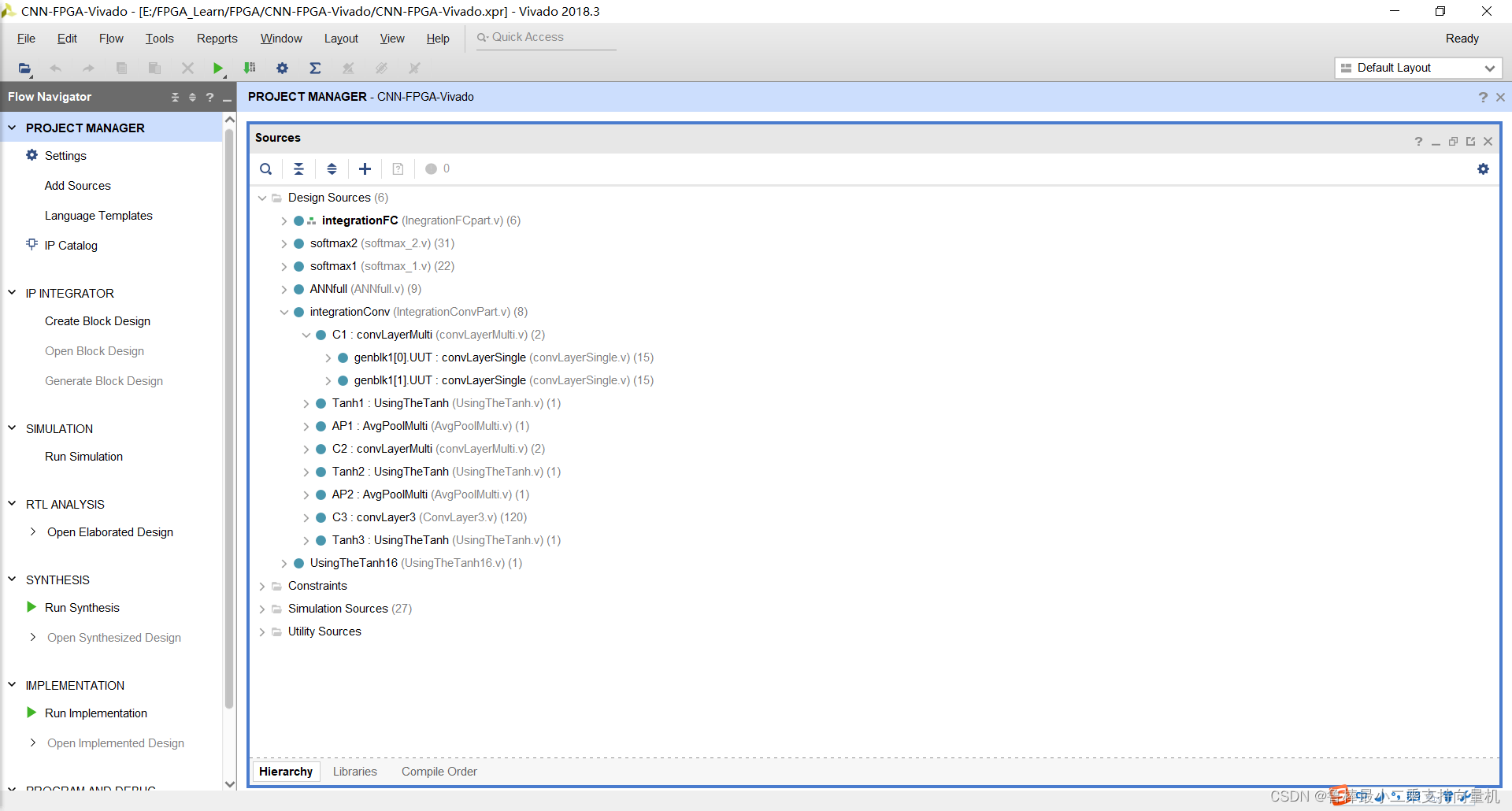
可以看到完整的工程文件包含如下图:
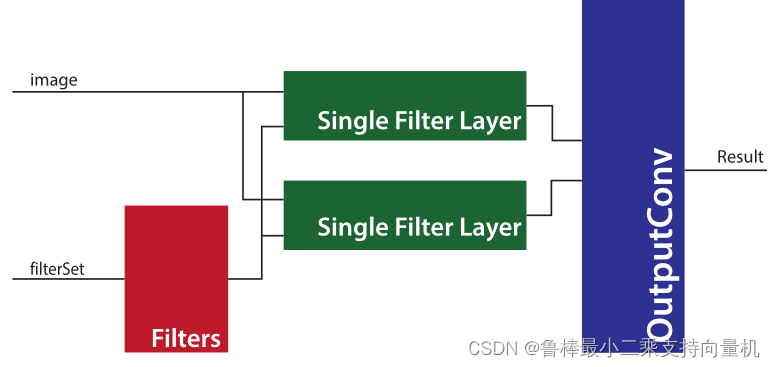
自顶而下分析卷积层的设计过程
图为该项目的一个卷积层,其中包含了多个卷积核(Filter),模块的输入为图像矩阵和卷积核设置参数,输出为卷积提取的特征矩阵
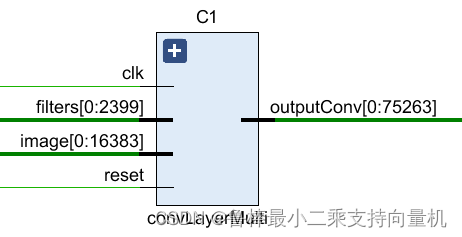
卷积层的原理图如图所示,其中filters的位宽为2400,image的位宽是16384,该层卷积的输出位宽是75264
- filters位宽计算:卷积核大小为5x5,卷积核个数为6,数据位宽为float16(16bits),所以5x5x6x16=2400
- image位宽计算:手写数字图像大小为32x32,数据位宽为float16,所以32x32x16=16384
- outputConv位宽计算:28x28x6x16=75264,式中28x28表示卷积层输出特征矩阵的长和宽,6表示卷积核的数量,数据位宽是float16
- 补充卷积输出特征尺寸计算:m=[(n-k+2xp)/s]+1,n表示输入图像或特征矩阵的尺寸,k表示卷积核的尺寸,s表示卷积核滑动的步长(stride),p表示填充(padding)。例如,图像大小为32x32,卷积核大小为5x5,步长为1,m=[(32-5+2x0)/1]+1=28
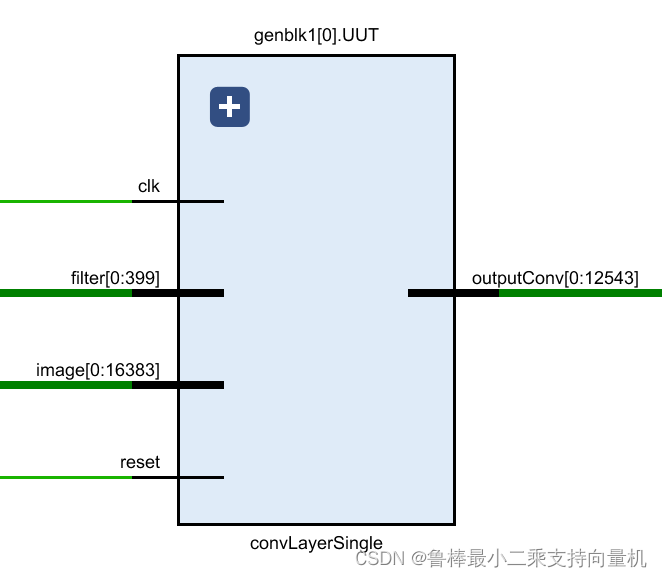
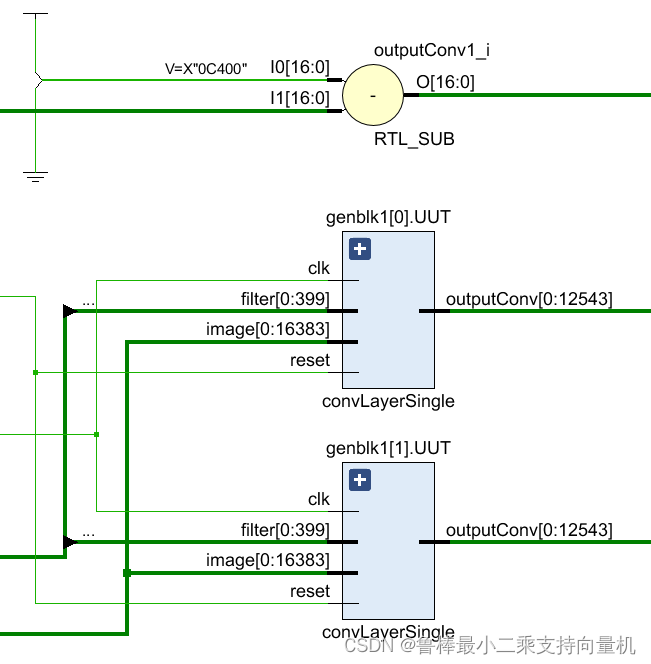
单个卷积核层的设计如图,输入为图像矩阵image和单个卷积核filter,输出卷积核处理的特征矩阵

原理图如图所示,filter的位宽为400,image的位宽是16384,输出位宽是12544
- filters位宽计算:卷积核大小为5x5,卷积核个数为1,数据位宽为float16,所以5x5x1x16=400
- image位宽计算:手写数字图像大小为32x32,数据位宽为float16,所以32x32x16=16384
- outputConv位宽计算:28x28x1x16=12544,式中28x28表示卷积层输出特征矩阵的长和宽,1表示卷积核的数量,数据位宽是float16
卷积单元如图所示,输入为卷积核filter和卷积核窗口覆盖的图像image,计算输出该窗口提取的特征
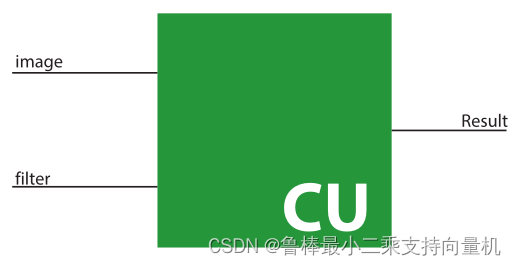
原理图如图所示,filter的位宽为400,卷积核窗口覆盖的图像image的位宽是400,输出位宽是16
- filters位宽计算:卷积核大小为5x5,卷积核个数为1,数据位宽为float16,所以5x5x1x16=400
- image位宽计算:手写数字图像大小为32x32,卷积核窗口覆盖的图像大小为5x5,数据位宽为float16,所,5x5x16=400
- result位宽计算:输出结果为float16数据类型的数,具体计算见 2.4 Processing Element 章节

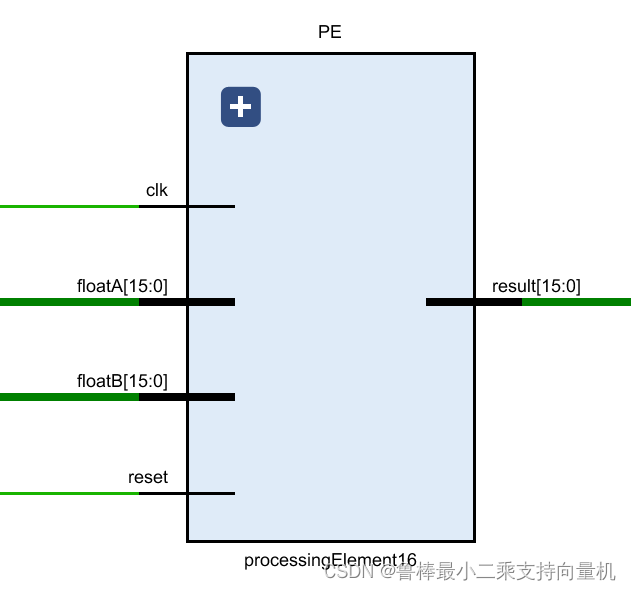
卷积单元具体实现如图所示,即相乘相加操作。卷积计算具体操作就是点乘,本质就是乘法和加法。图中输入为float16类型数据A和B,输出float16数据类型的结果

原理图如图所示,可以看到输入floatA和floatB,以及输出result位宽均为16
自底向上分析每个模块的功能和具体实现
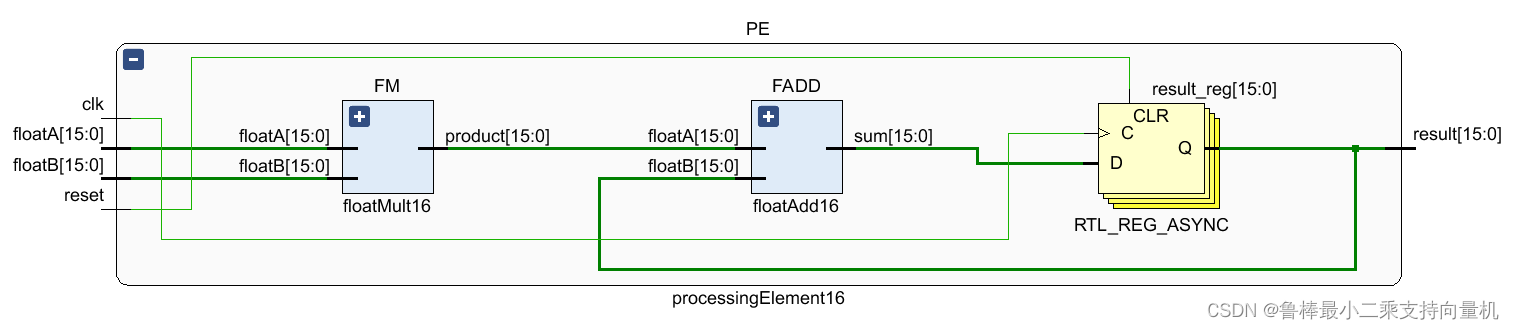
如图所示Processing Element由FM(floatMult16),FADD(floatAdd16),result_reg三个单元组成
- FM(floatMult16)单元是执行两个float16数据的乘法
- FADD(floatAdd16)单元是执行两个float16数据的加法
- result_reg寄存器,存放的是新的求和,将电路从组合逻辑转为同步时序电路,保证数据的同步
卷积单元完整的顶层原理图如图所示,对一个卷积核和该卷积核覆盖的图像区域(可以称为窗口)进行计算,输出一个计算结果(float16)

Single Filter Layer原理图如图所示,由1个RF selector和14个CU组成,该部分是计算一个卷积核与一幅图像的卷积,输出卷积提取的完整图像的特征。
RF selector的作用:将卷积核覆盖的图像区域(可以称为窗口)的数据对应传输给14个CU,输入图像尺寸为32x32x16,卷积核大小为5x5x16,卷积核滑动步长为1,此时一幅完整图像将产生28x28个窗口数据,每个窗口数据为5x5x16。因为14个CU是并行计算的,故RF selector输出位宽为14x5x5x16=5600
为什么选择使用14个CU,作者给出的解释是:LUT的数量在单个或多个卷积核模块中呈指数增长,实验对比后,最终决定使用CU的数量等于输出特征中单行像素数量的一半。例如,输入图像32x32,卷积核5x5,输出特征为28x28,故CU的数量等于28/2=14

Multi Filter Layer原理图如图所示,由2个convLayerSingle组成,即并行度为2。上述内容可知Multi Filter Layer的输入是图像和6个卷积核,因此6个卷积核分为2个一组,循环3次输入到convLayerSingle,即每次执行2个卷积核与图像的卷积
新建工程,操作如图所示:
输入工程名字和工程路径,如图:
选择创建RTL工程,如图:

直接点击Next:
继续点击Next:
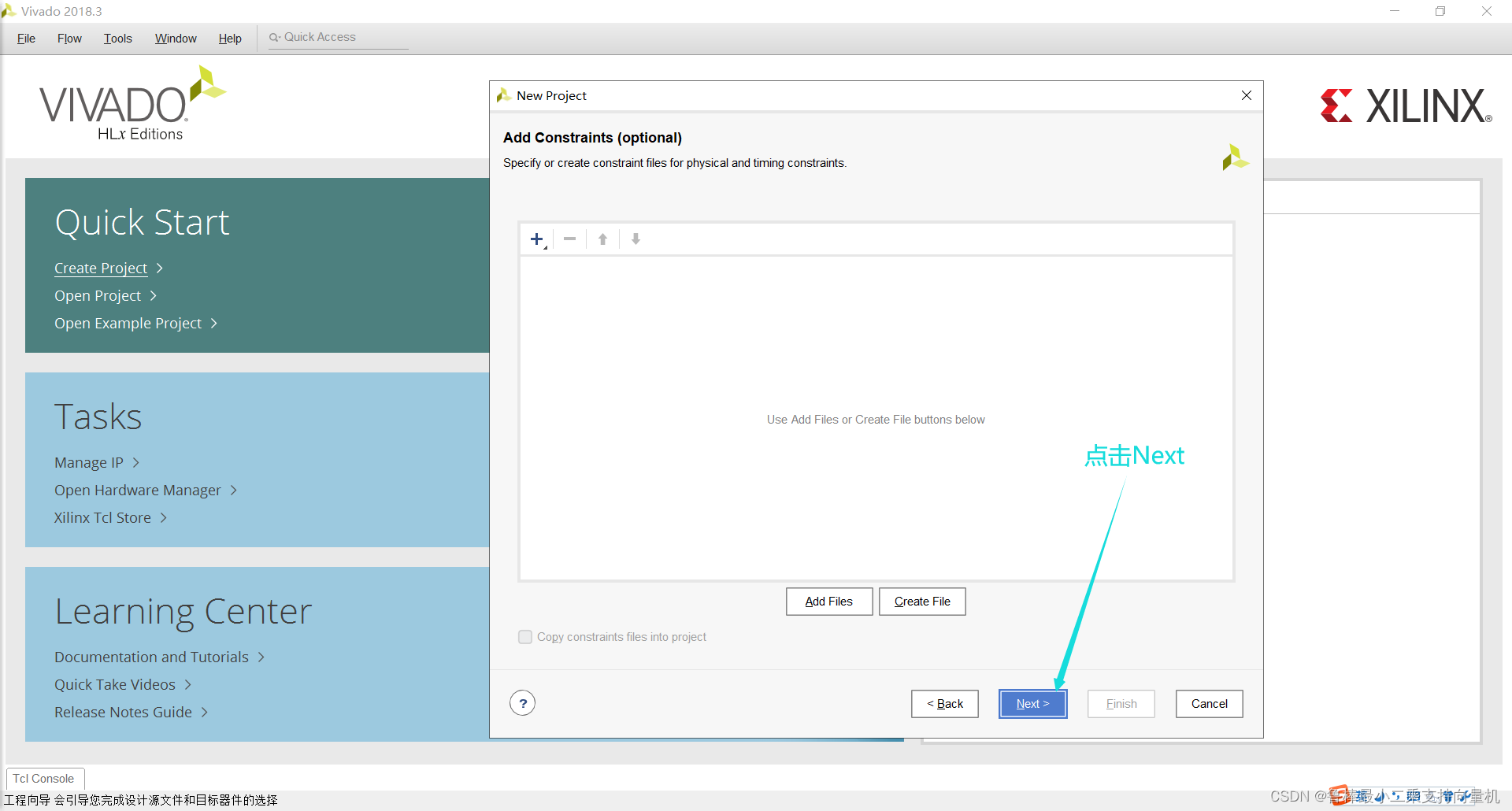
添加芯片型号,操作如图:

完成创建:
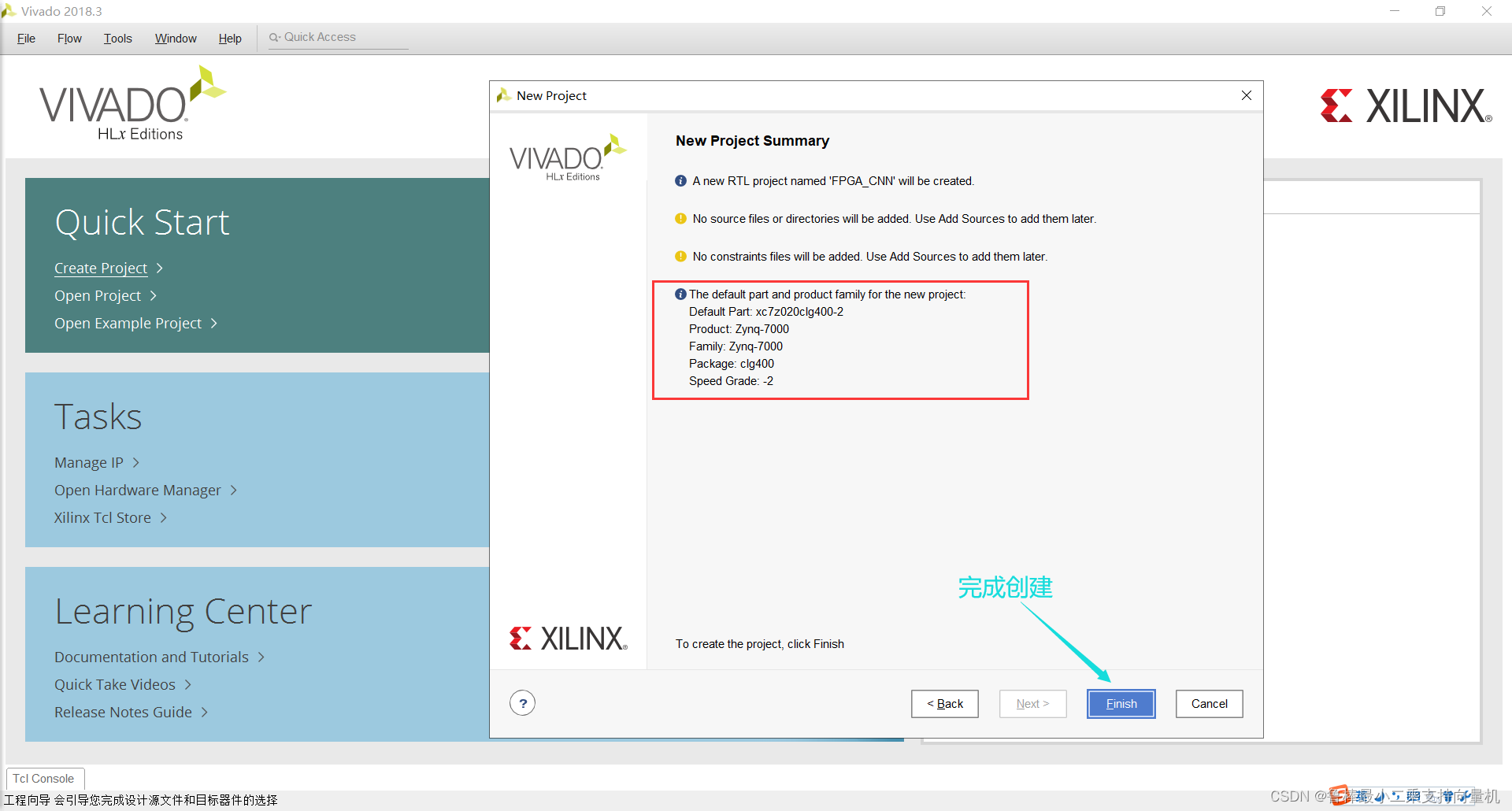
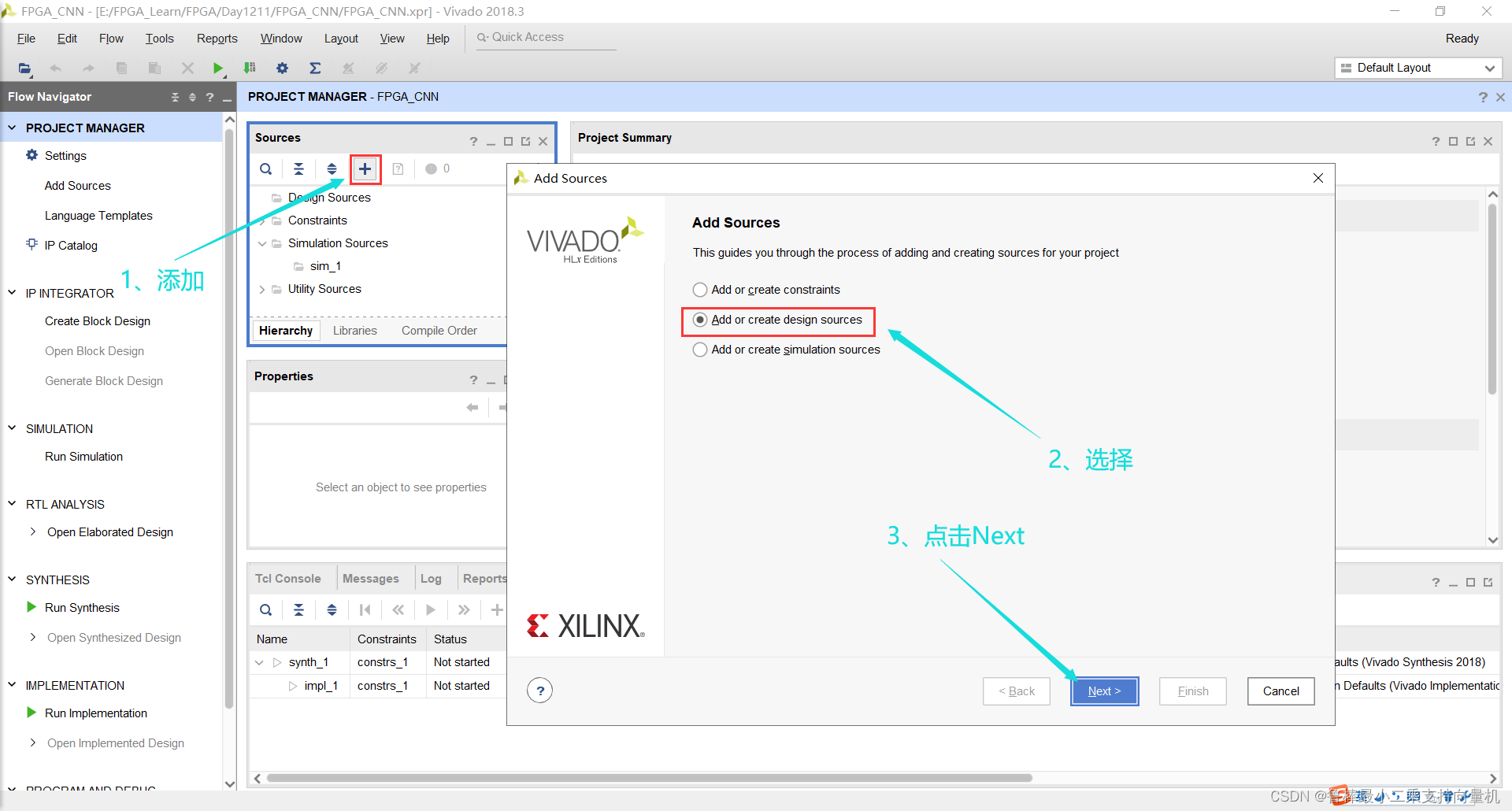
创建工程文件,操作如图:
创建floatAdd16文件:
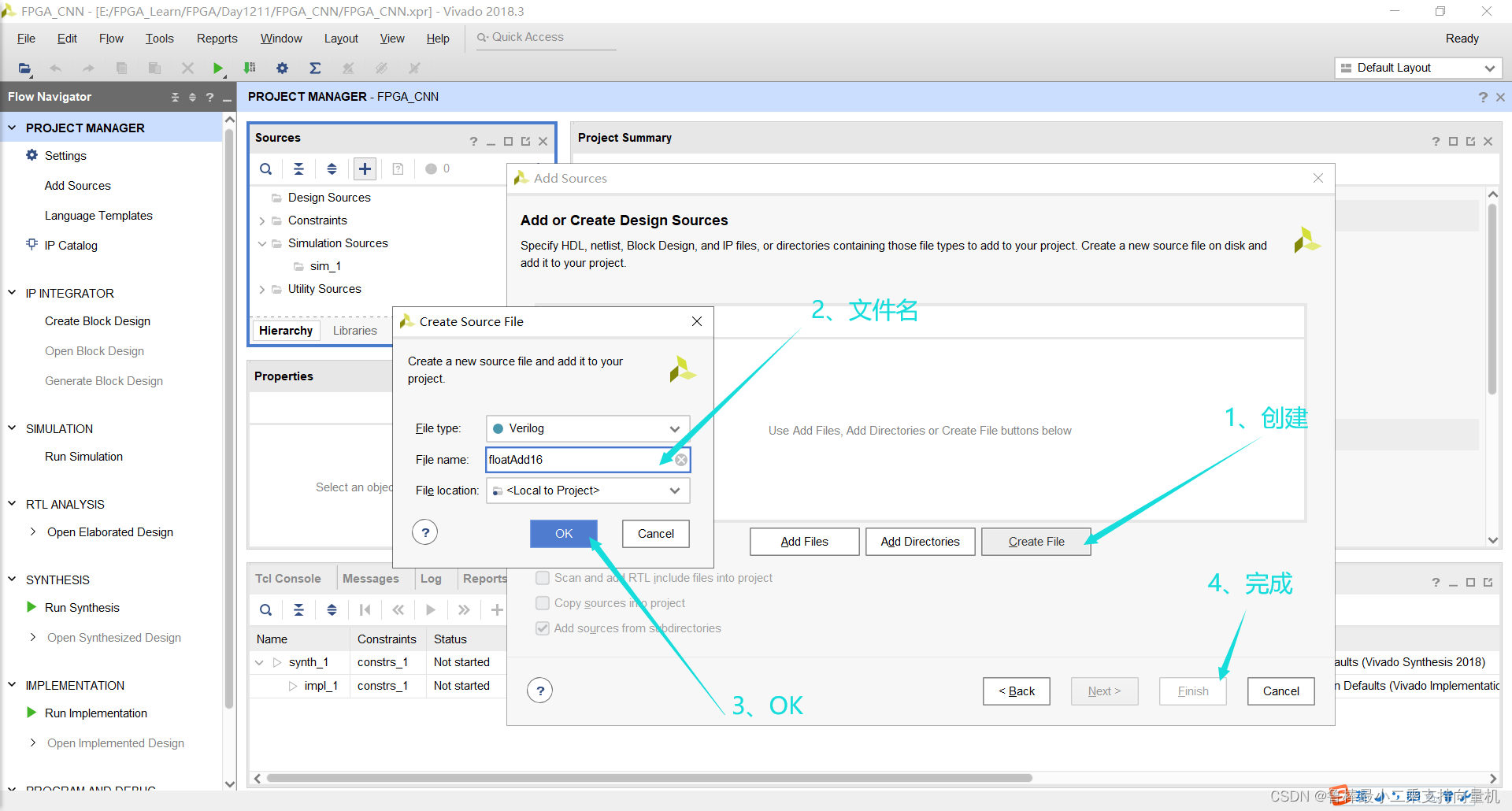
创建完成:
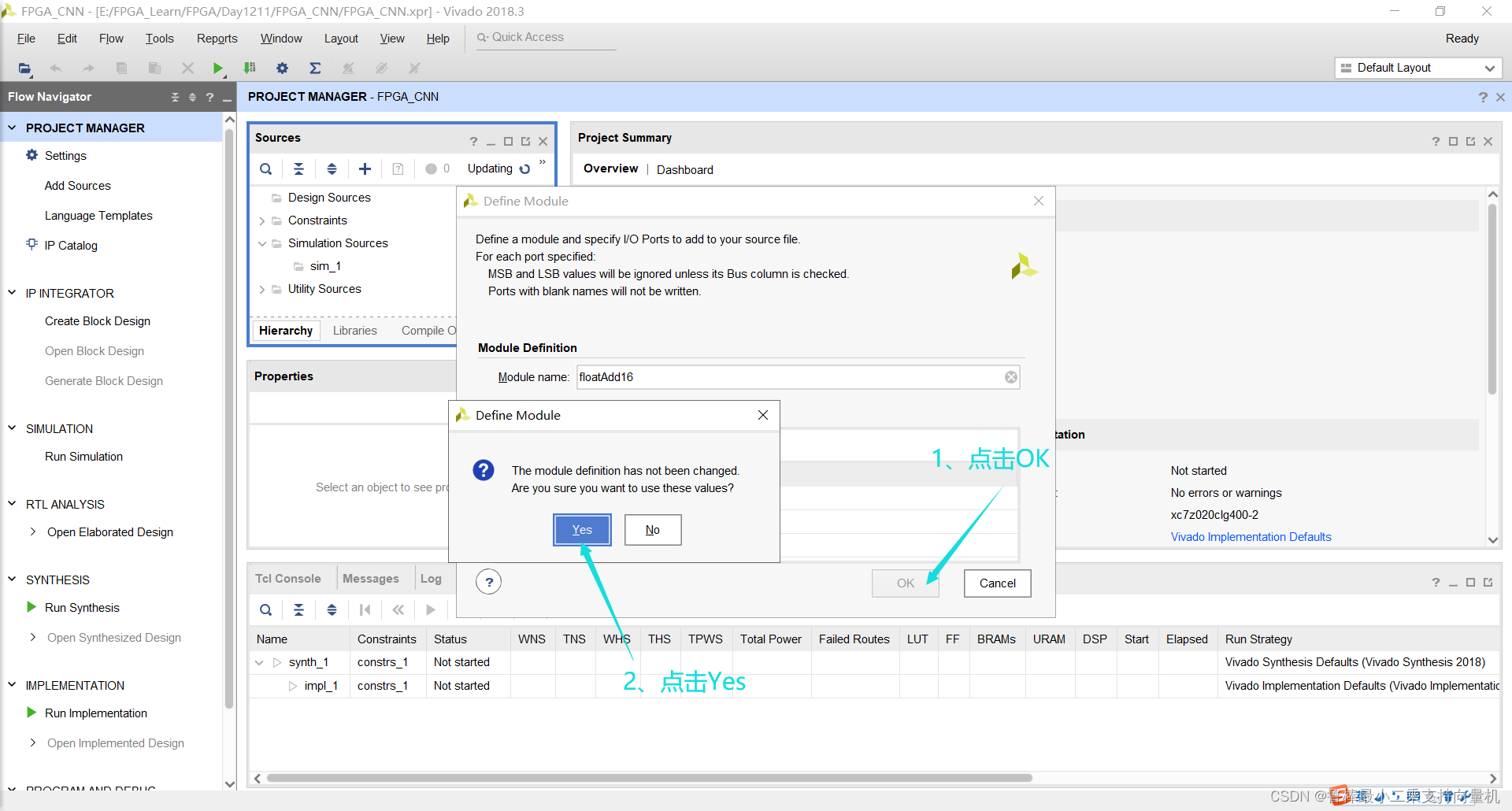
双击打开,输入如下代码:
如图所示:
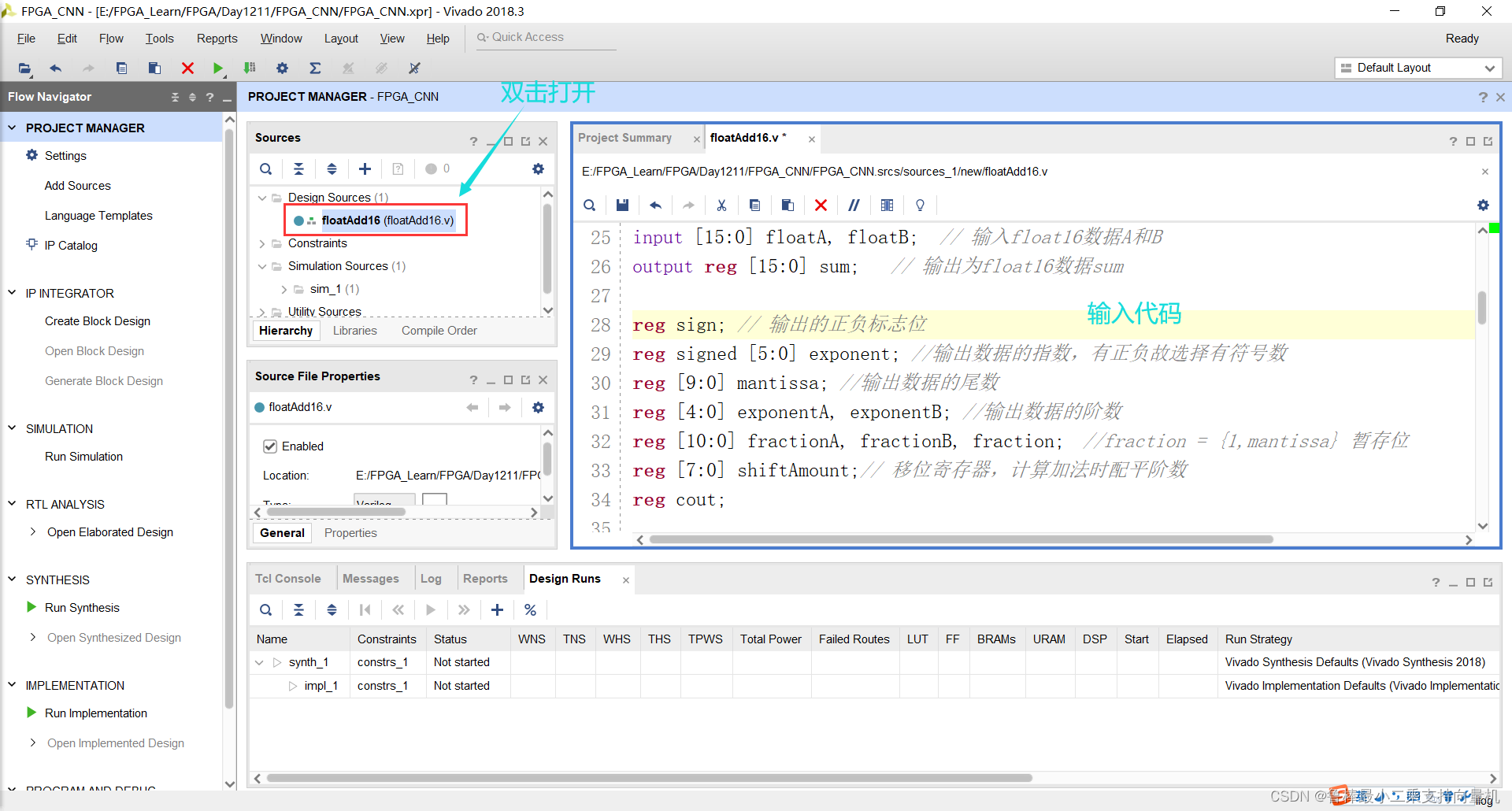
对设计进行分析,操作如图:
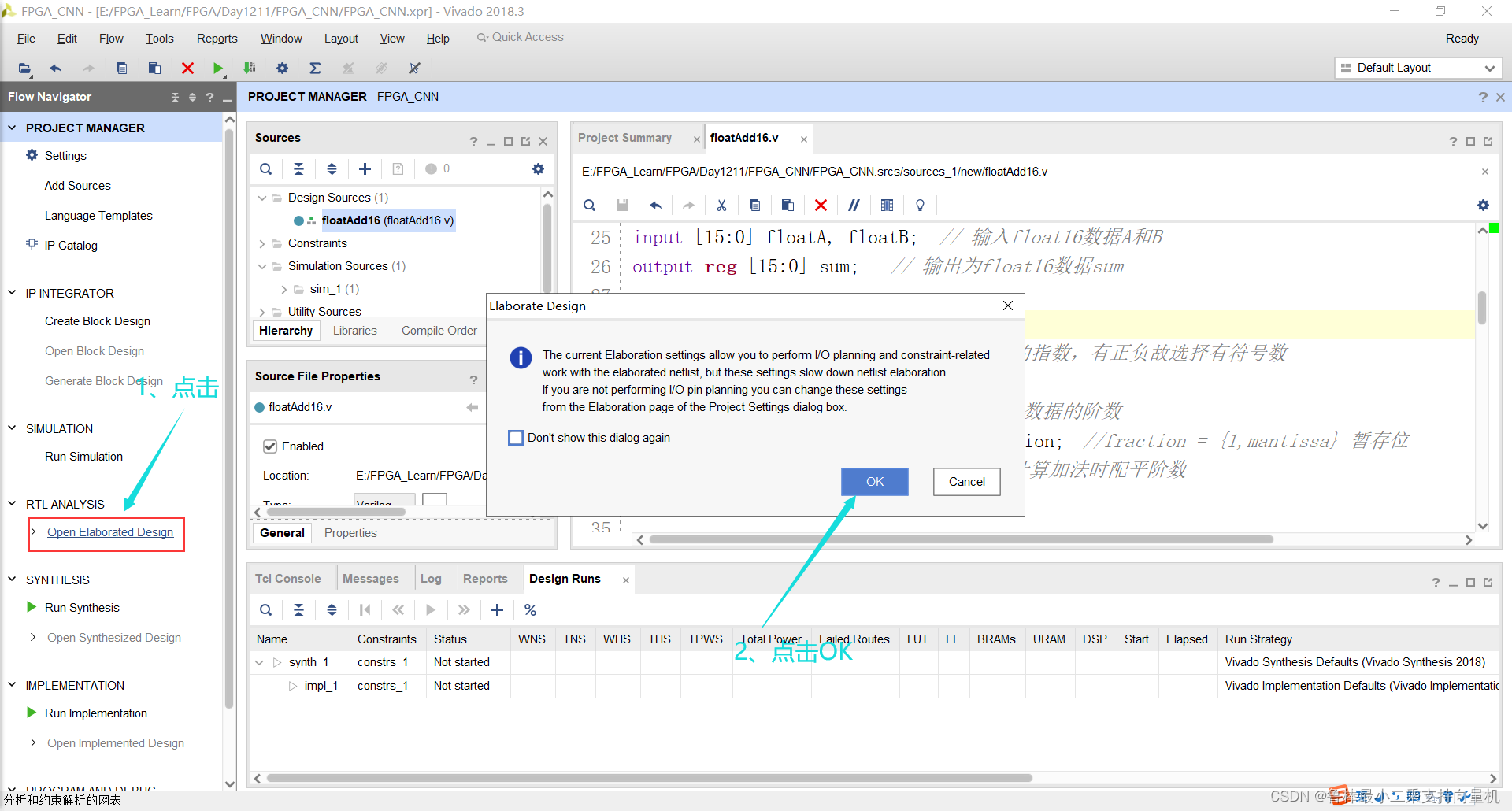
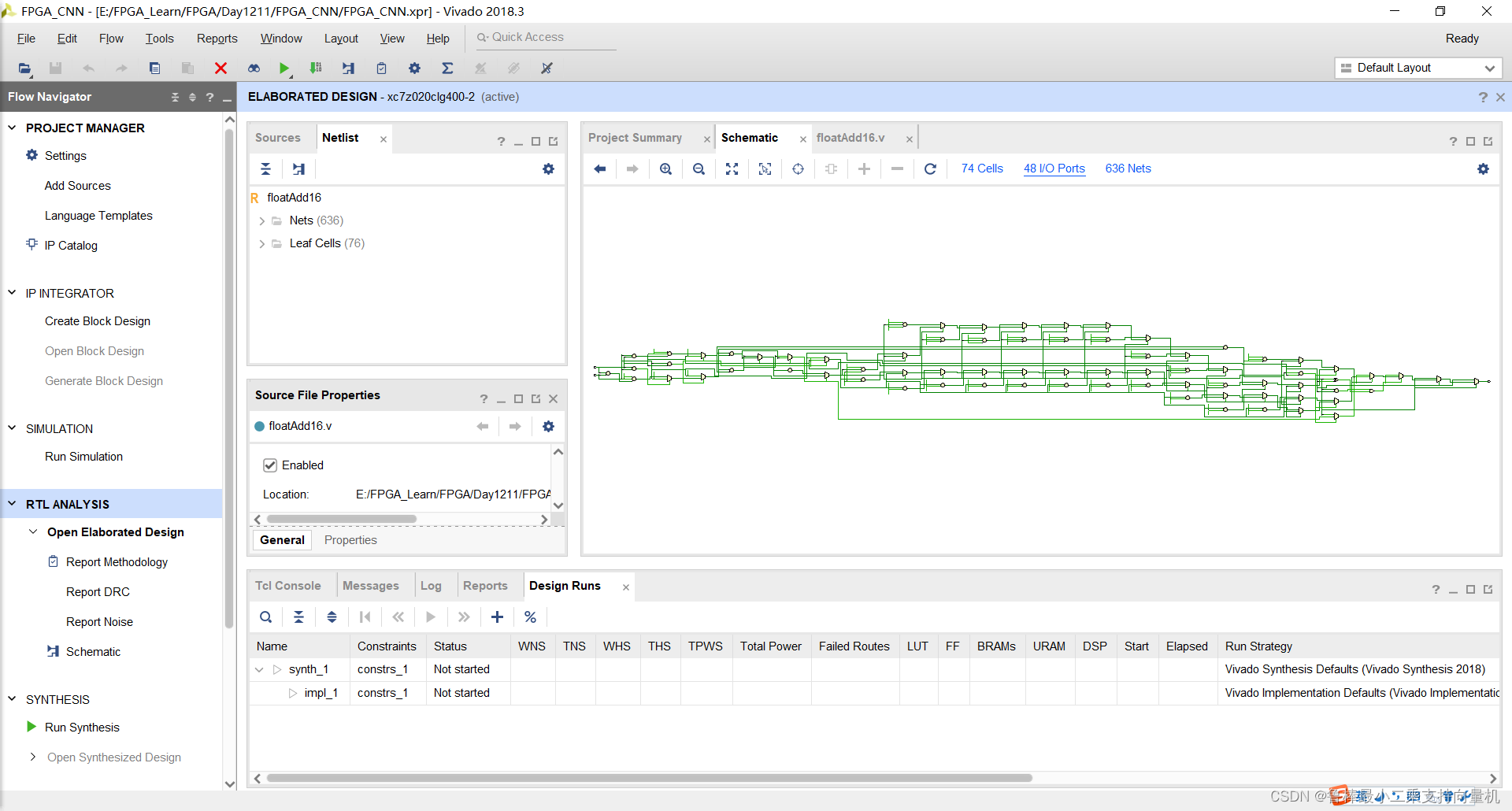
分析后的设计,Vivado自动生成原理图,如图:
对设计进行综合,操作如图:
综合完成后,弹出窗口如下,直接关闭:
创建TestBench,操作如图所示:
创建激励文件,输入文件名:
创建完成:
双击打开,输入激励代码:
如图所示:
开始进行仿真,操作如下:
仿真操作,如图:

调整波形,进行观察:
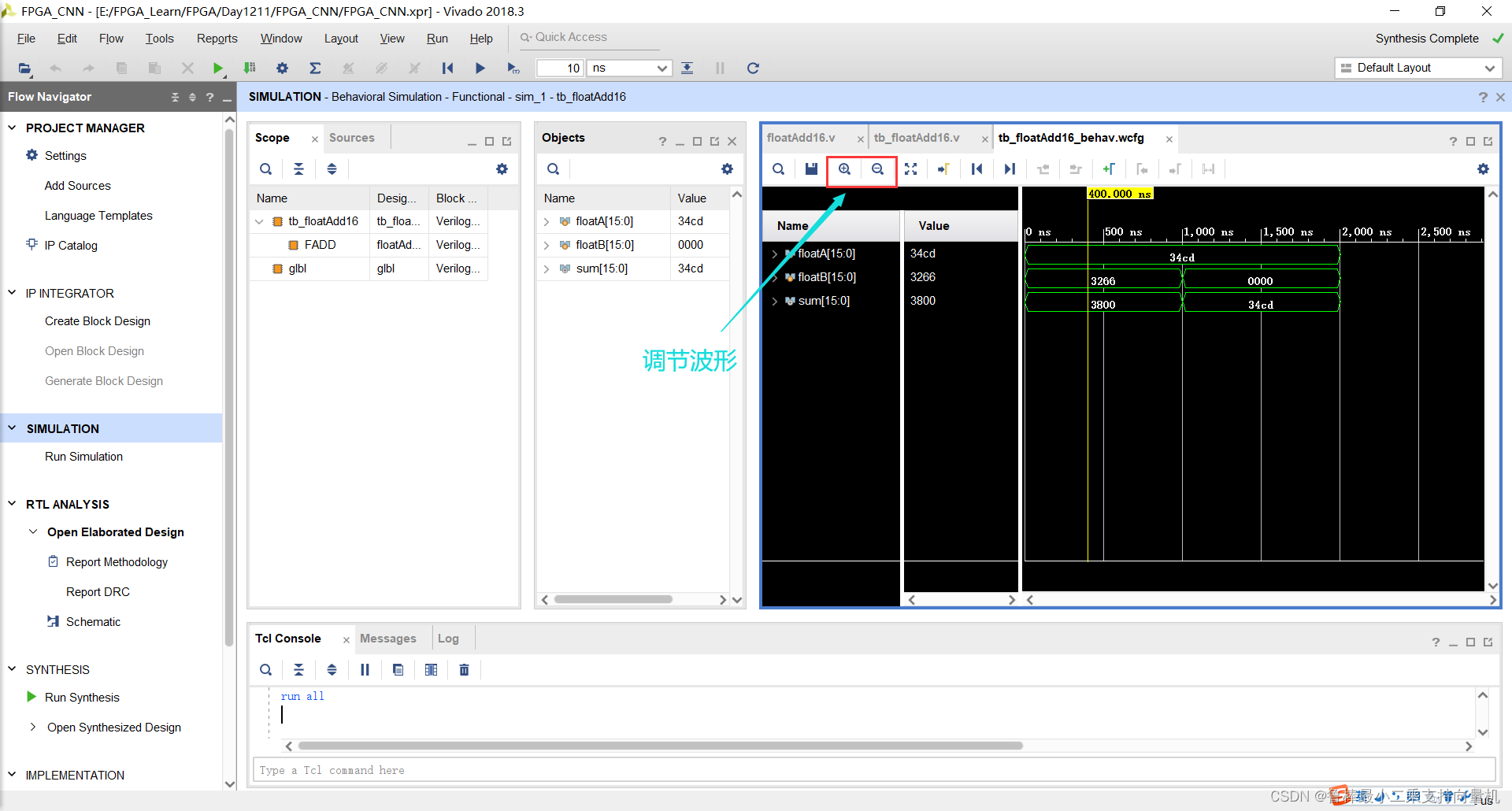
仿真波形如图:

关闭仿真:
点击OK:
创建floatMult16文件,如图:
双击打开,输入如下代码:
如图所示:
将floatMult16设置为顶层:
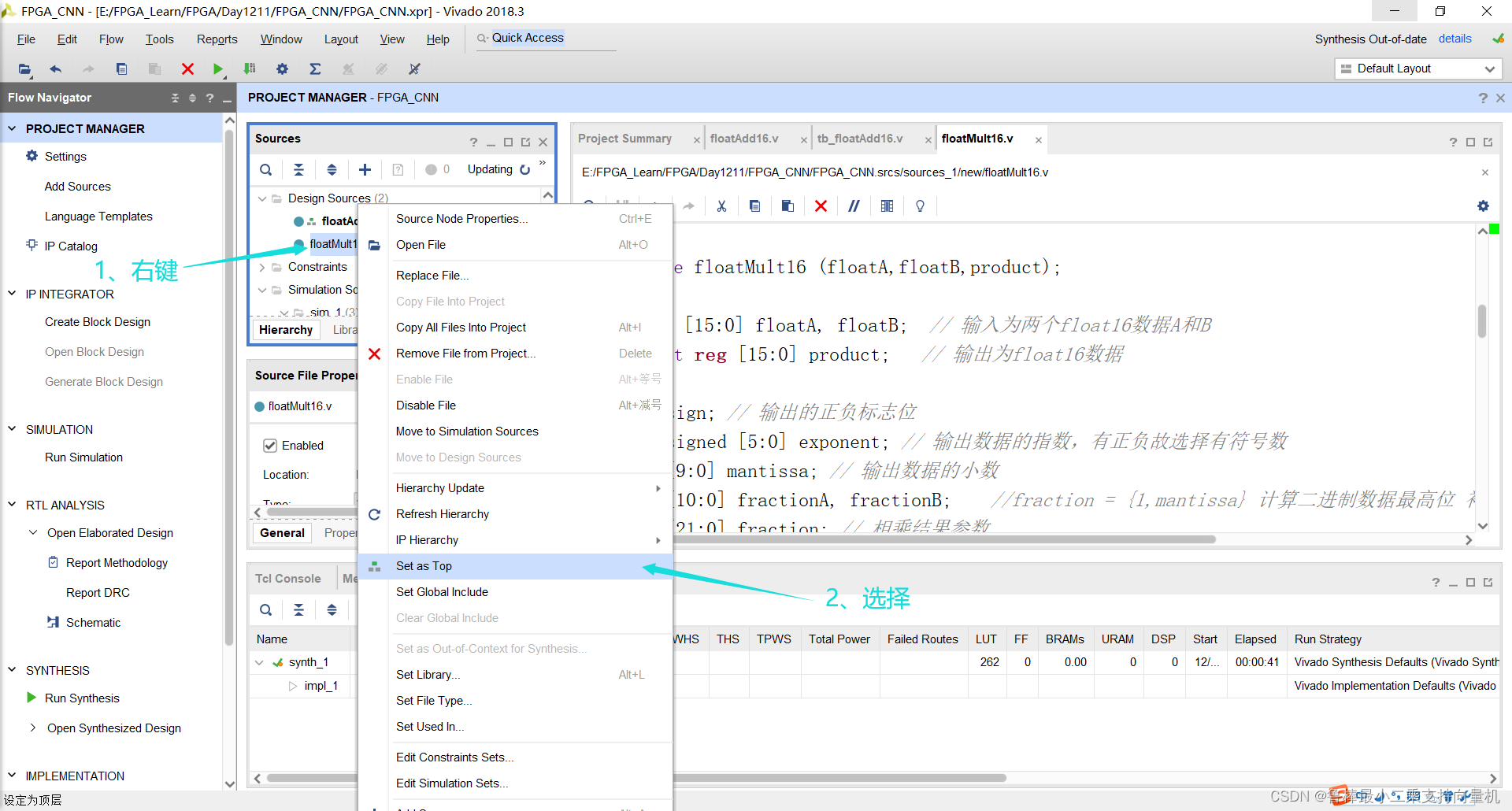
关闭上次的分析文件:
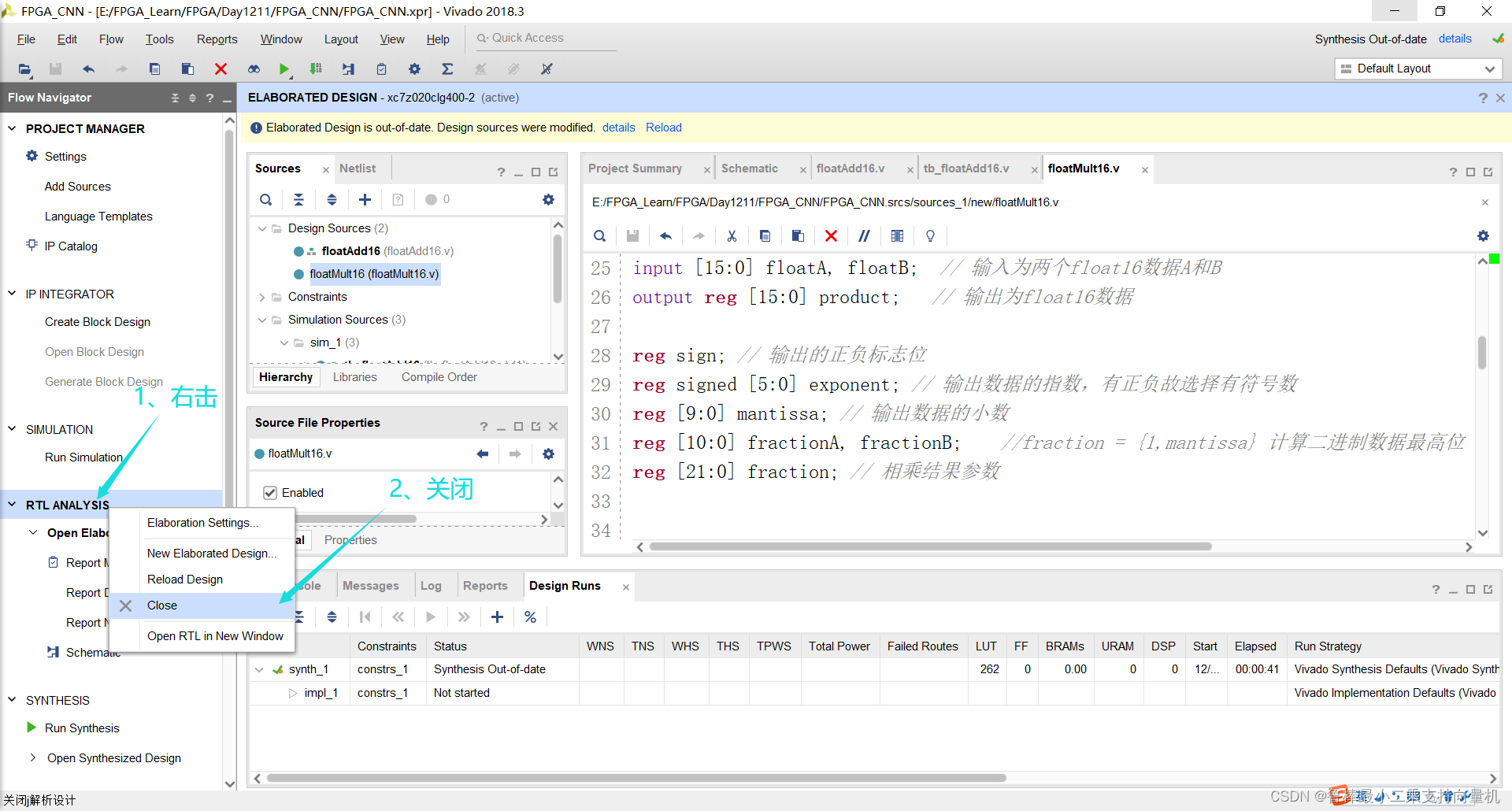
对设计进行分析,操作如图:

分析后的设计,Vivado自动生成原理图,如图:
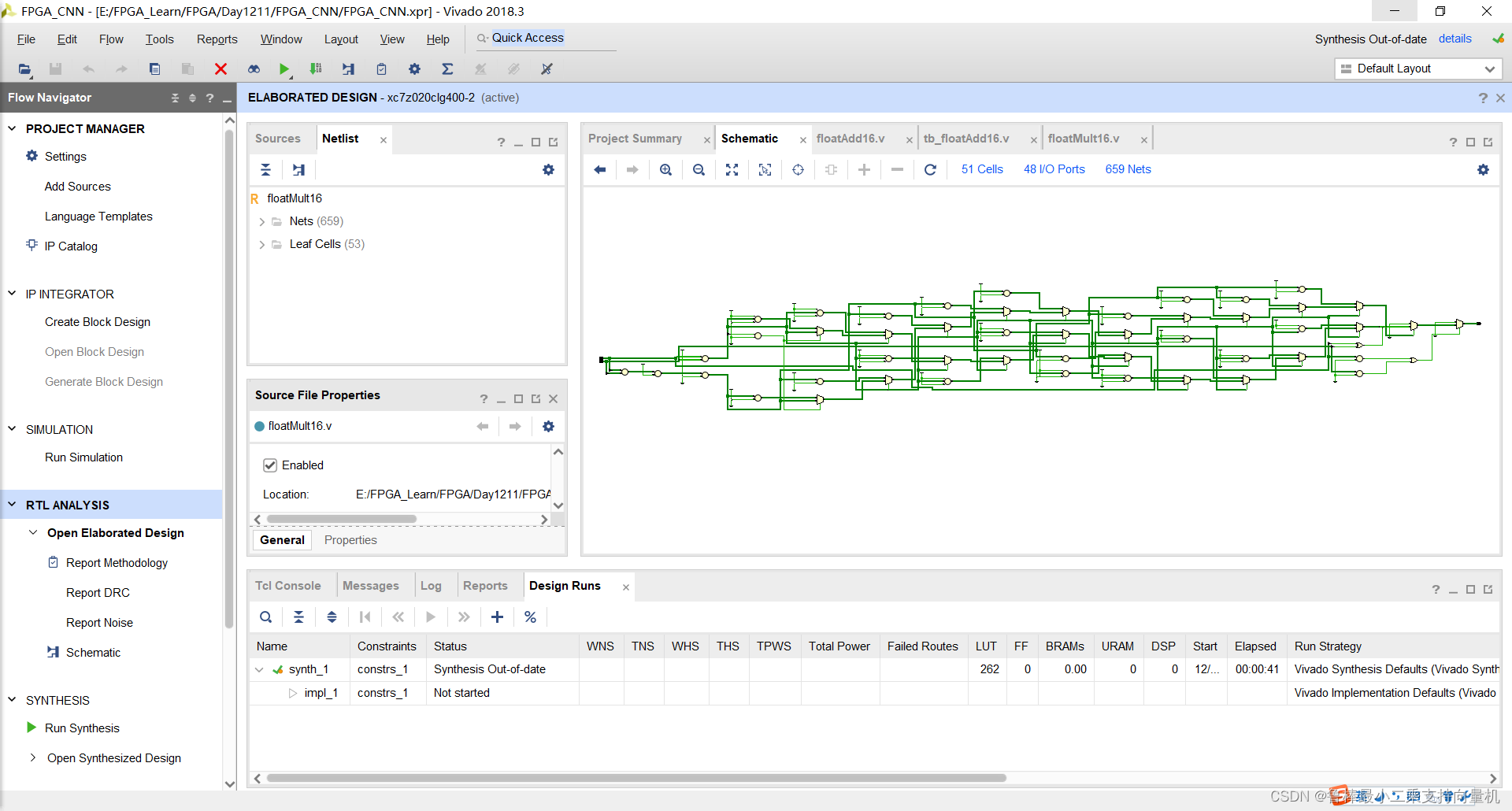
对设计进行综合,操作如图:
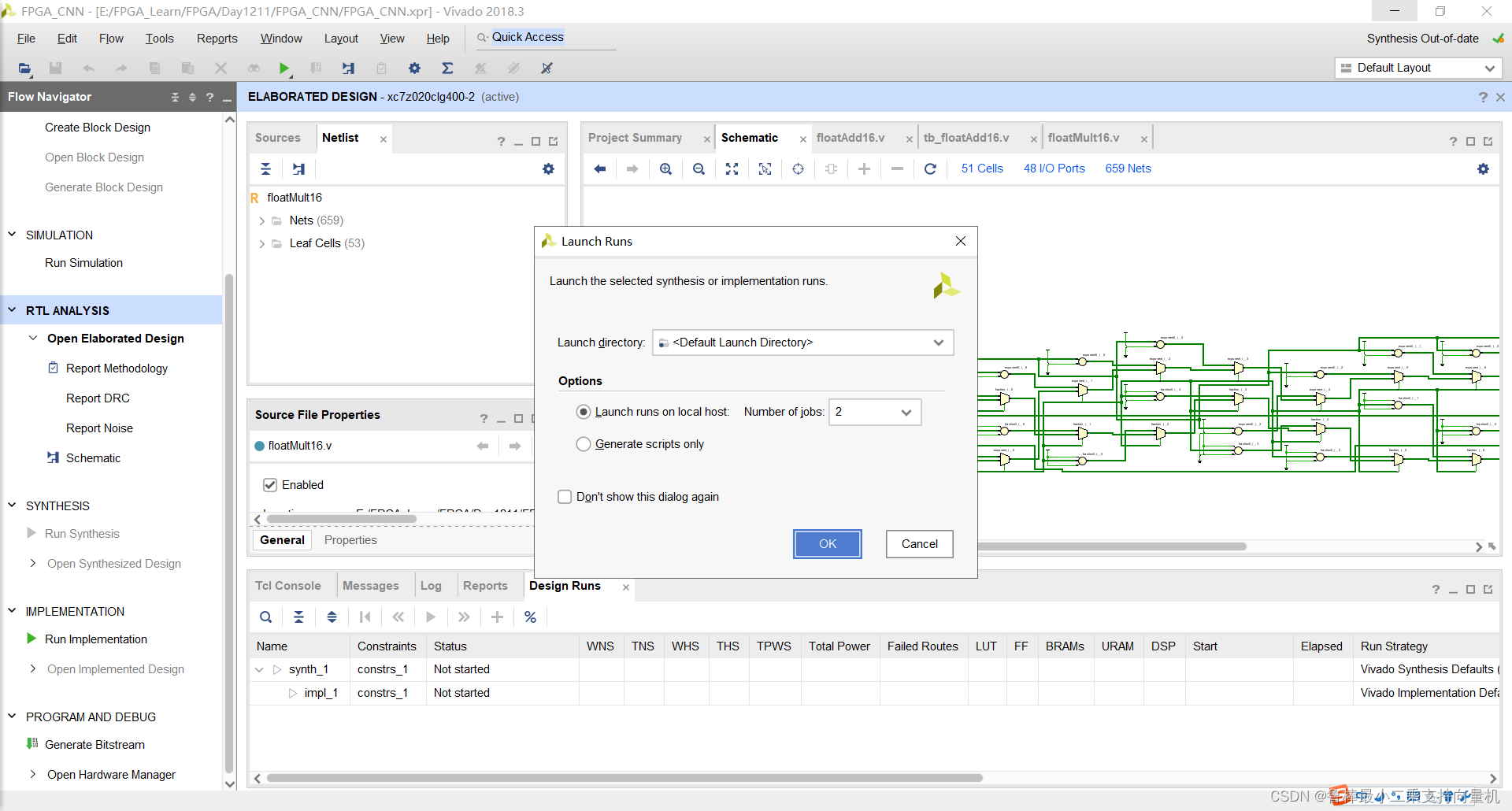
创建TestBench,操作如图所示:
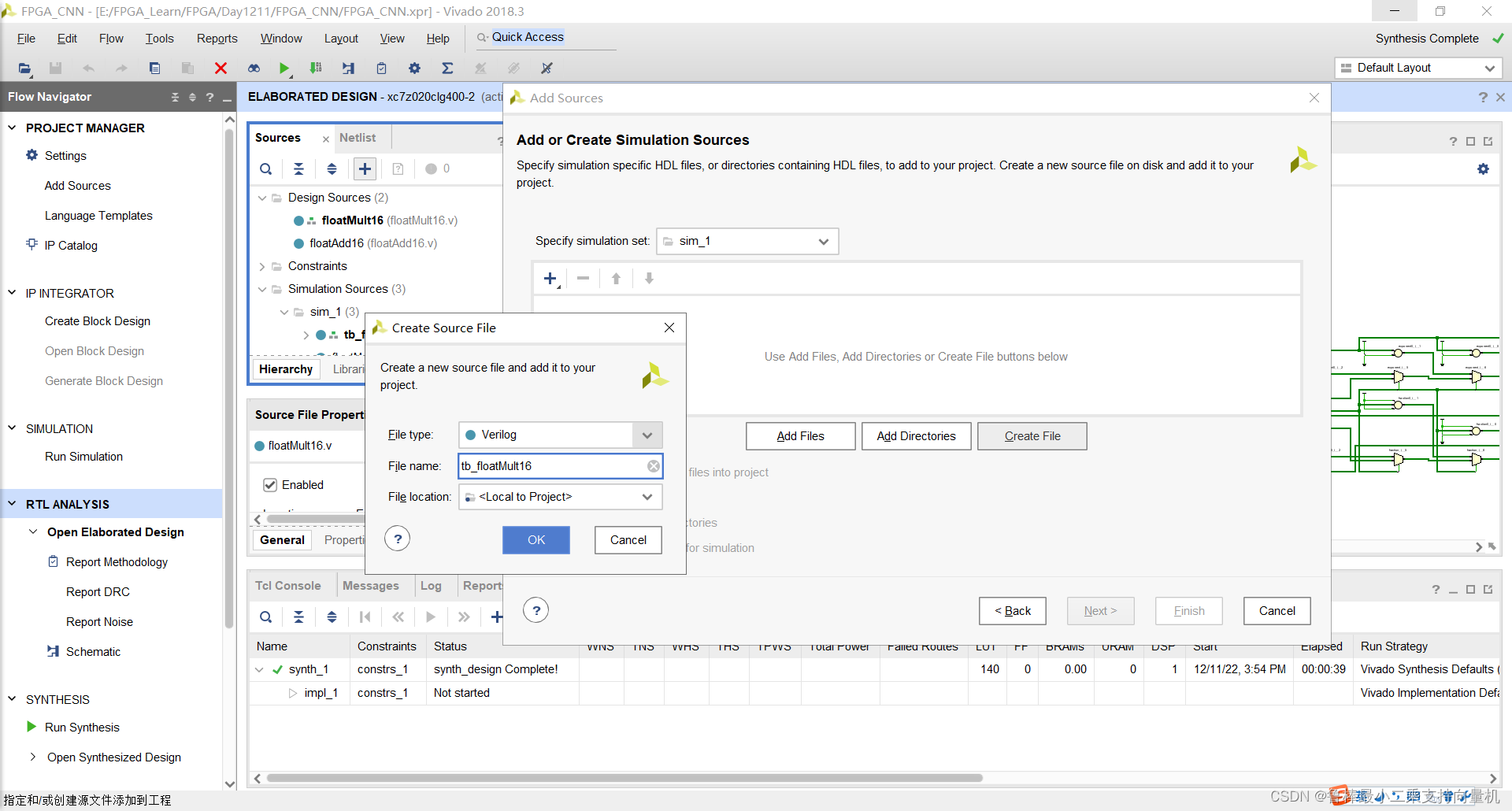
双击打开,输入激励代码:
如图所示:
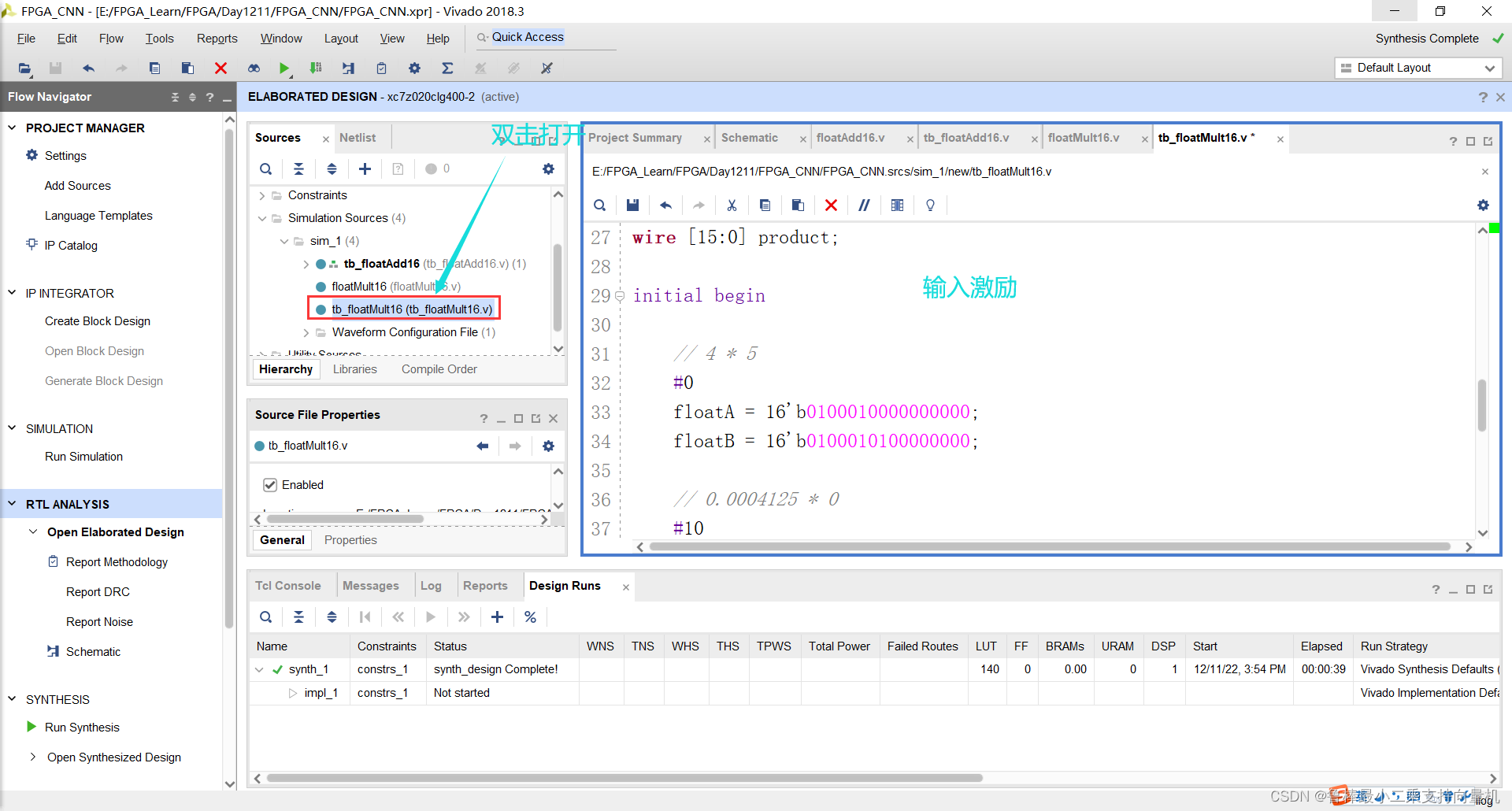
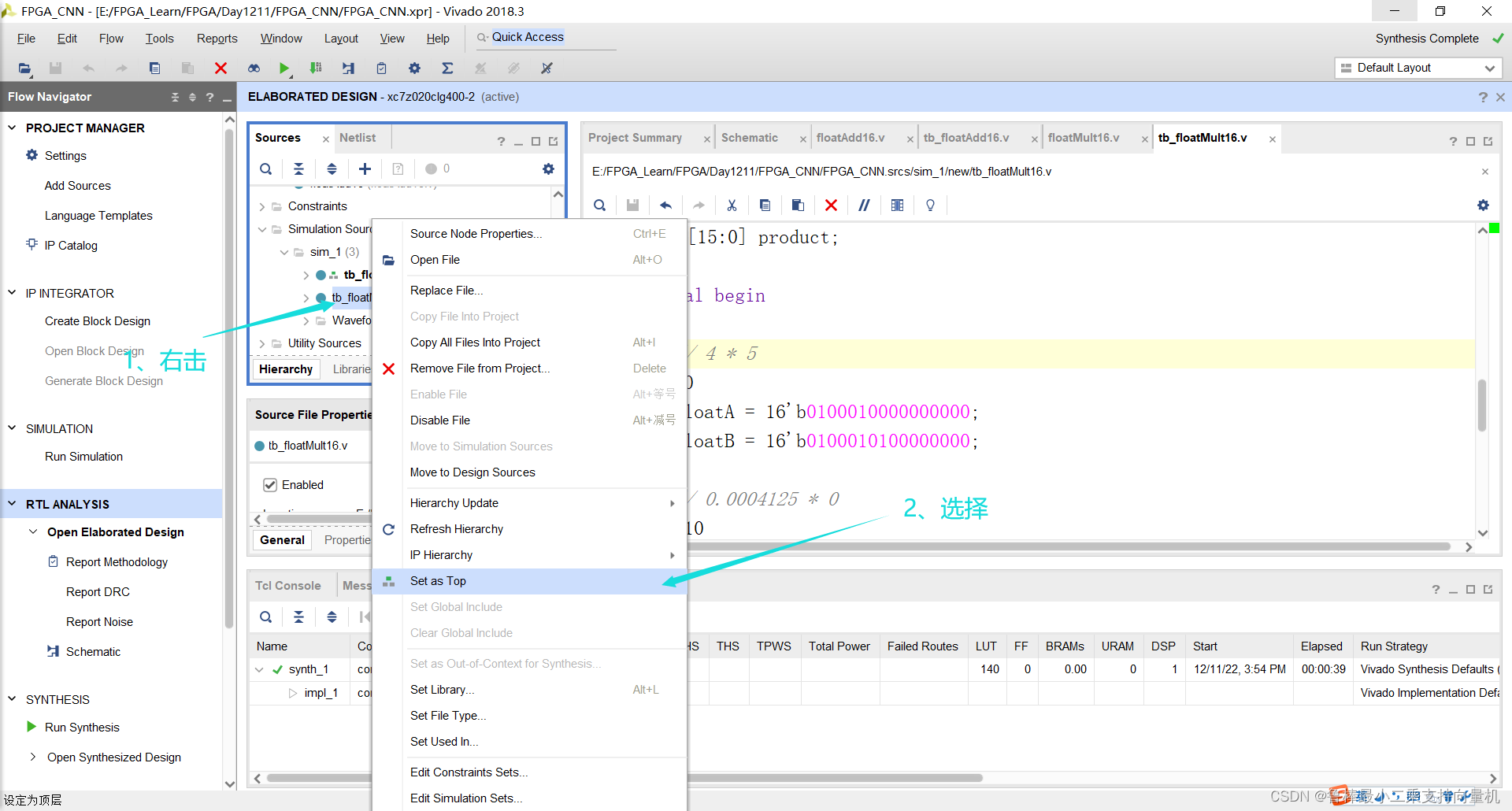
将tb_floatMult16设置为顶层:
开始进行仿真,操作如下:
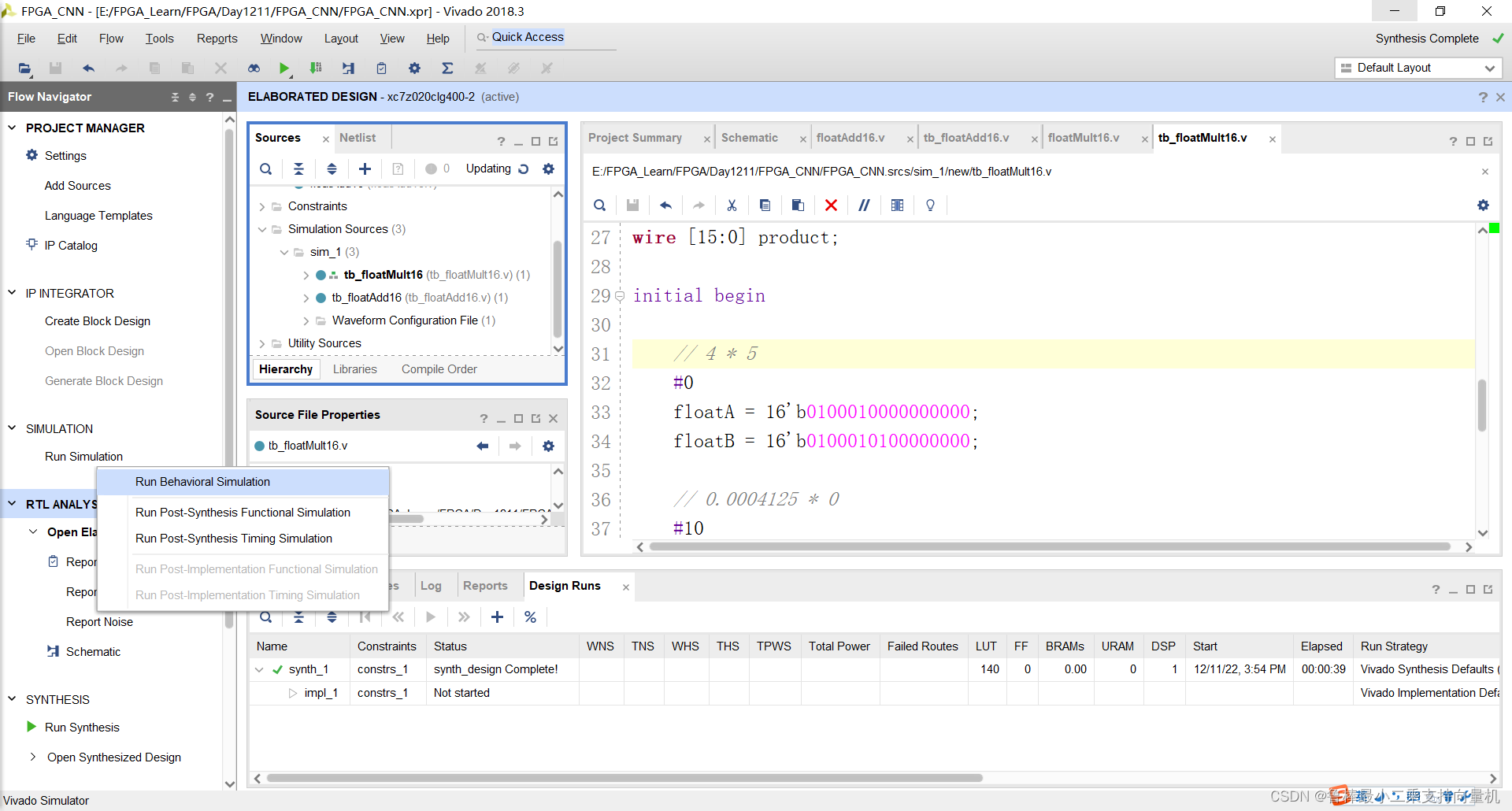
添加仿真对象,操作如图:
开始仿真,如图:
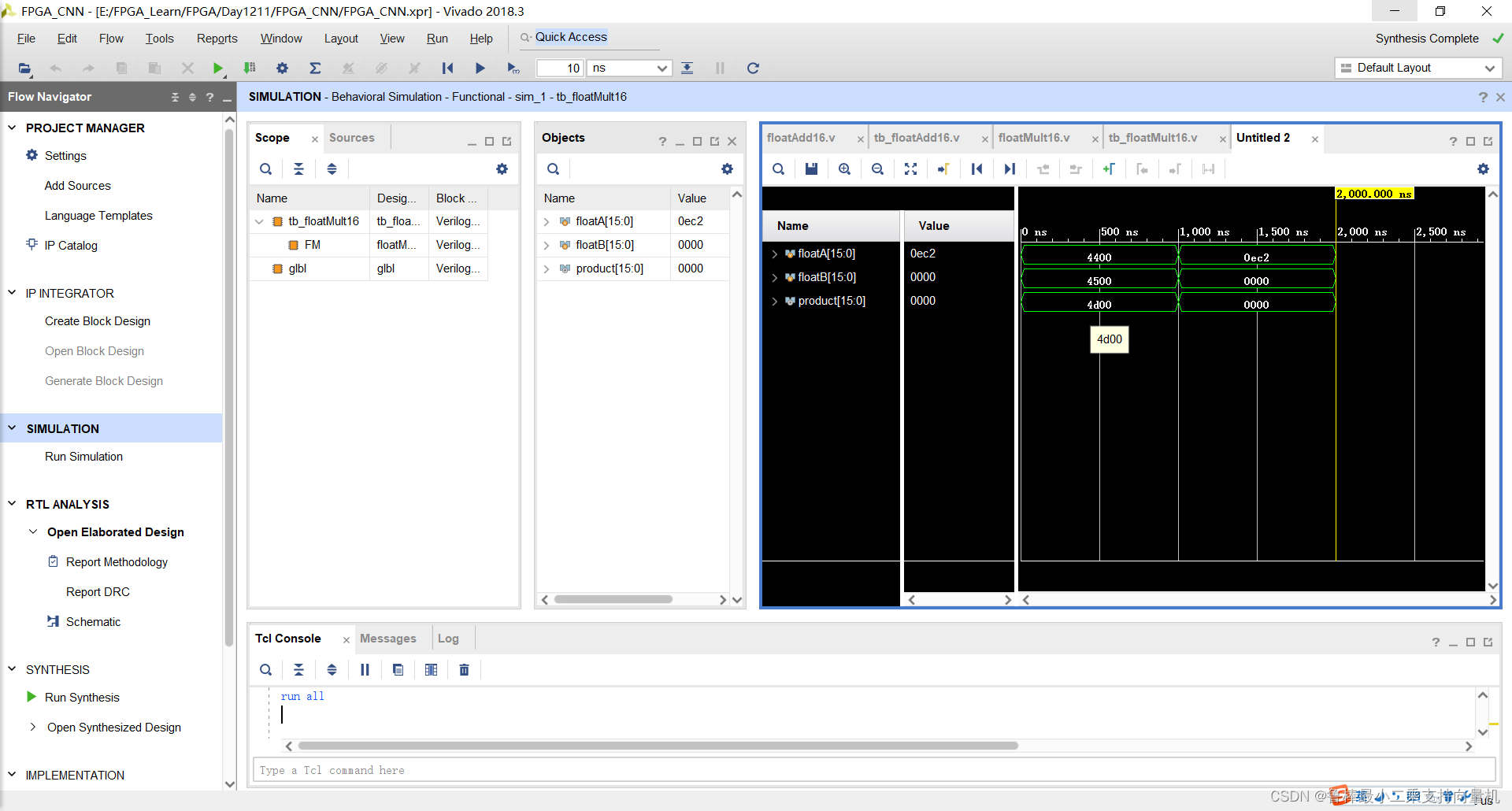
仿真波形,如图:
创建processingElement16文件,如图:
双击打开,输入如下代码:
如图所示:
关闭上次的分析文件:

将processingElement16设置为顶层:
对设计进行分析,操作如图:

分析后的设计,Vivado自动生成原理图,如图:

对设计进行综合,操作如图:
创建TestBench,操作如图所示:
双击打开,输入激励代码:
如图所示:
将tb_processingElement16设置为顶层:
开始进行仿真,操作如下:

开始仿真,如图:
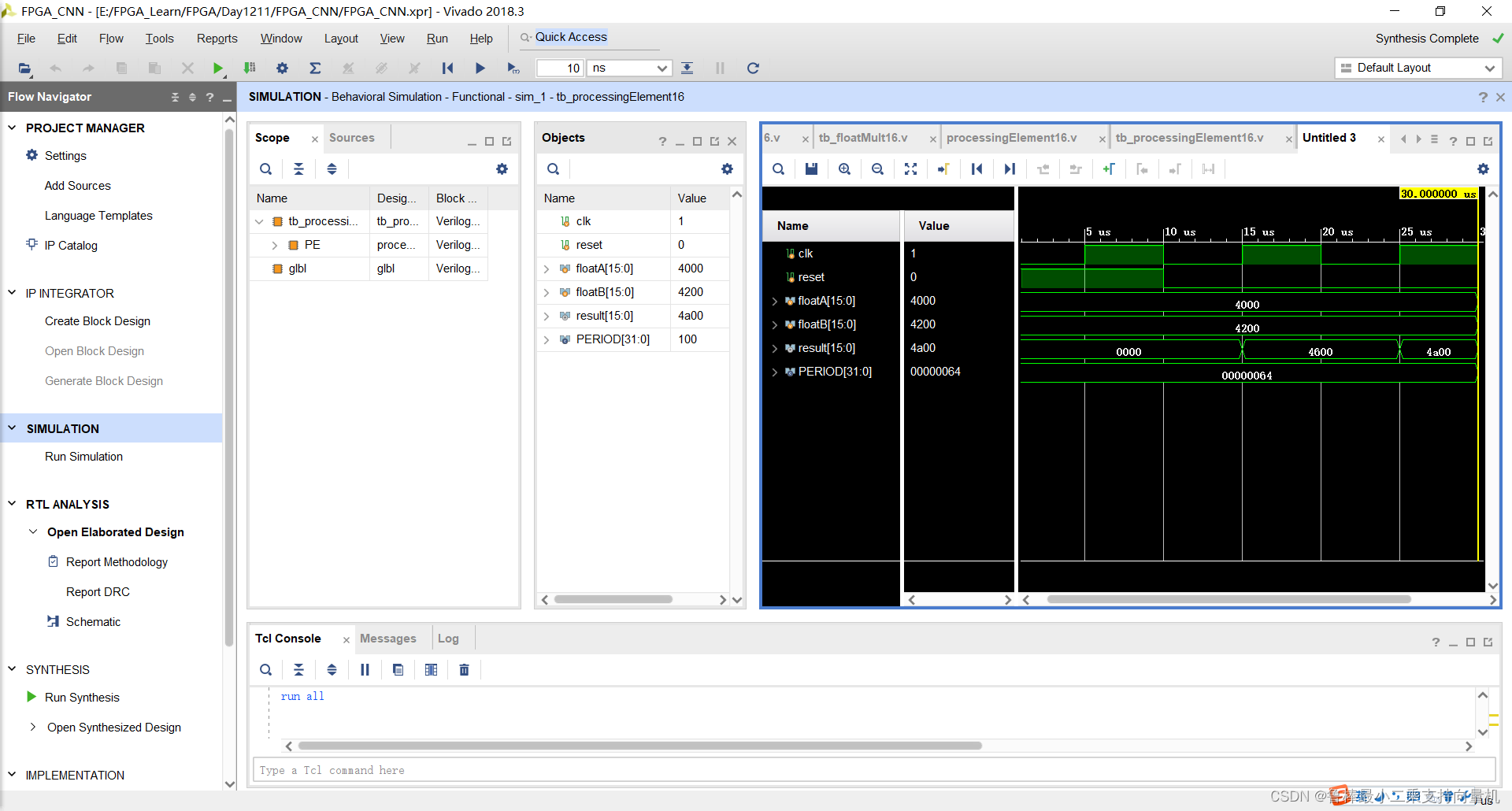
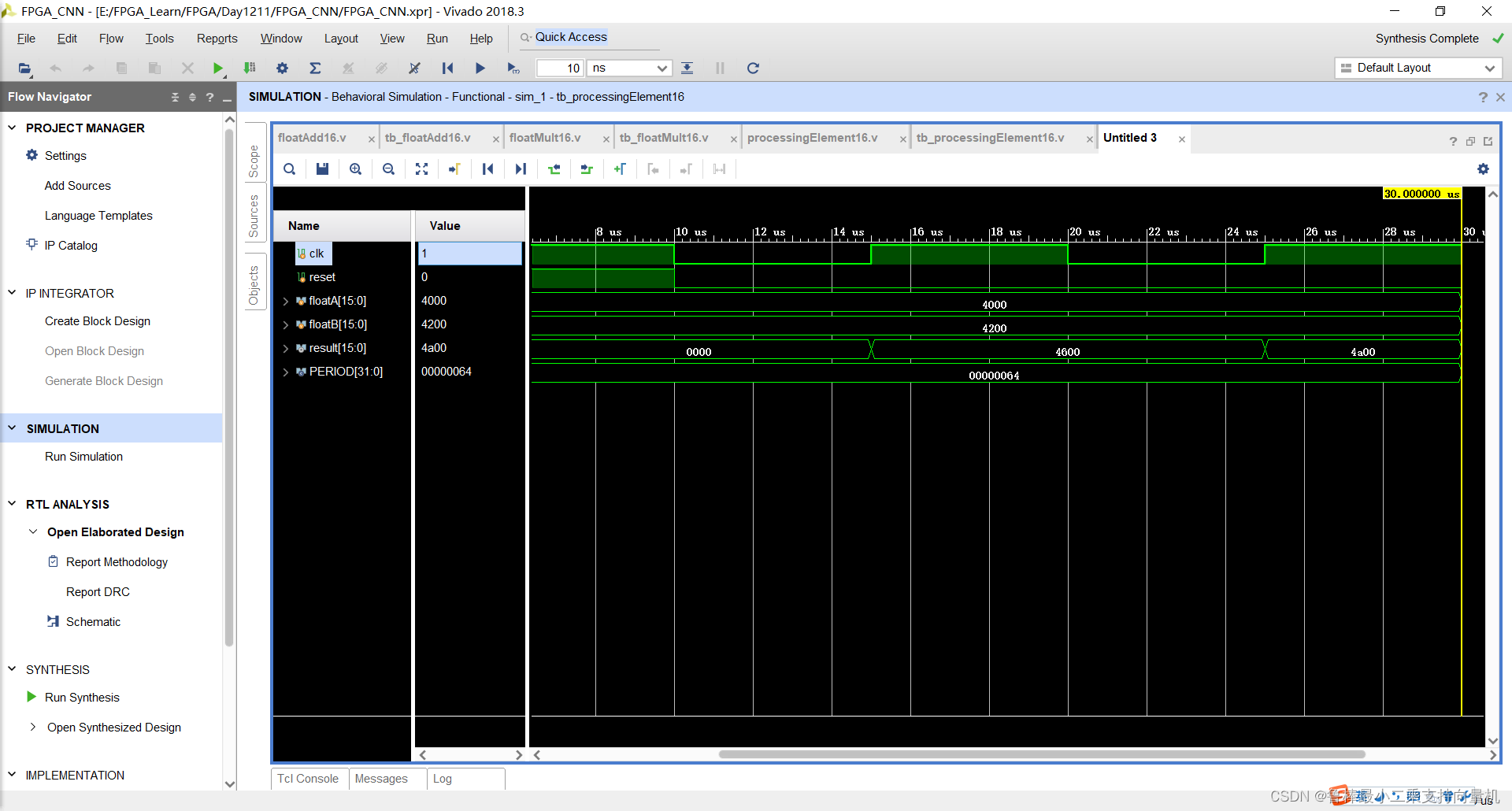
仿真波形,如图:
创建convUnit文件,如图:

双击打开,输入如下代码:
如图所示:
将convUnit设置为顶层:
关闭上次的分析文件:
对设计进行分析,操作如图:
分析后的设计,Vivado自动生成原理图,如图:
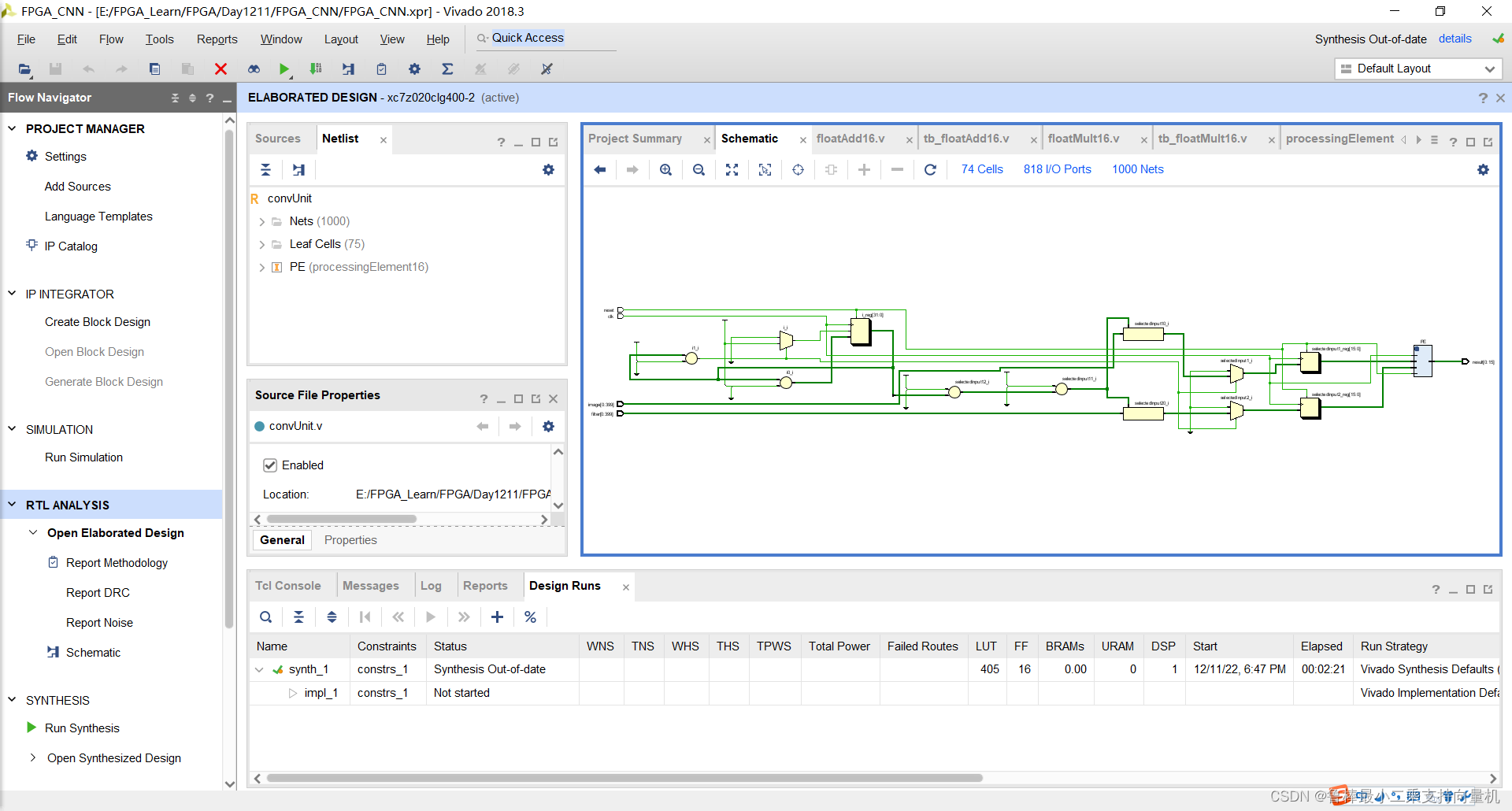
对设计进行综合,操作如图:
创建TestBench,操作如图所示:
双击打开,输入激励代码:
如图所示:
将tb_convUnit设置为顶层:
开始进行仿真,操作如下:
开始仿真,如图:
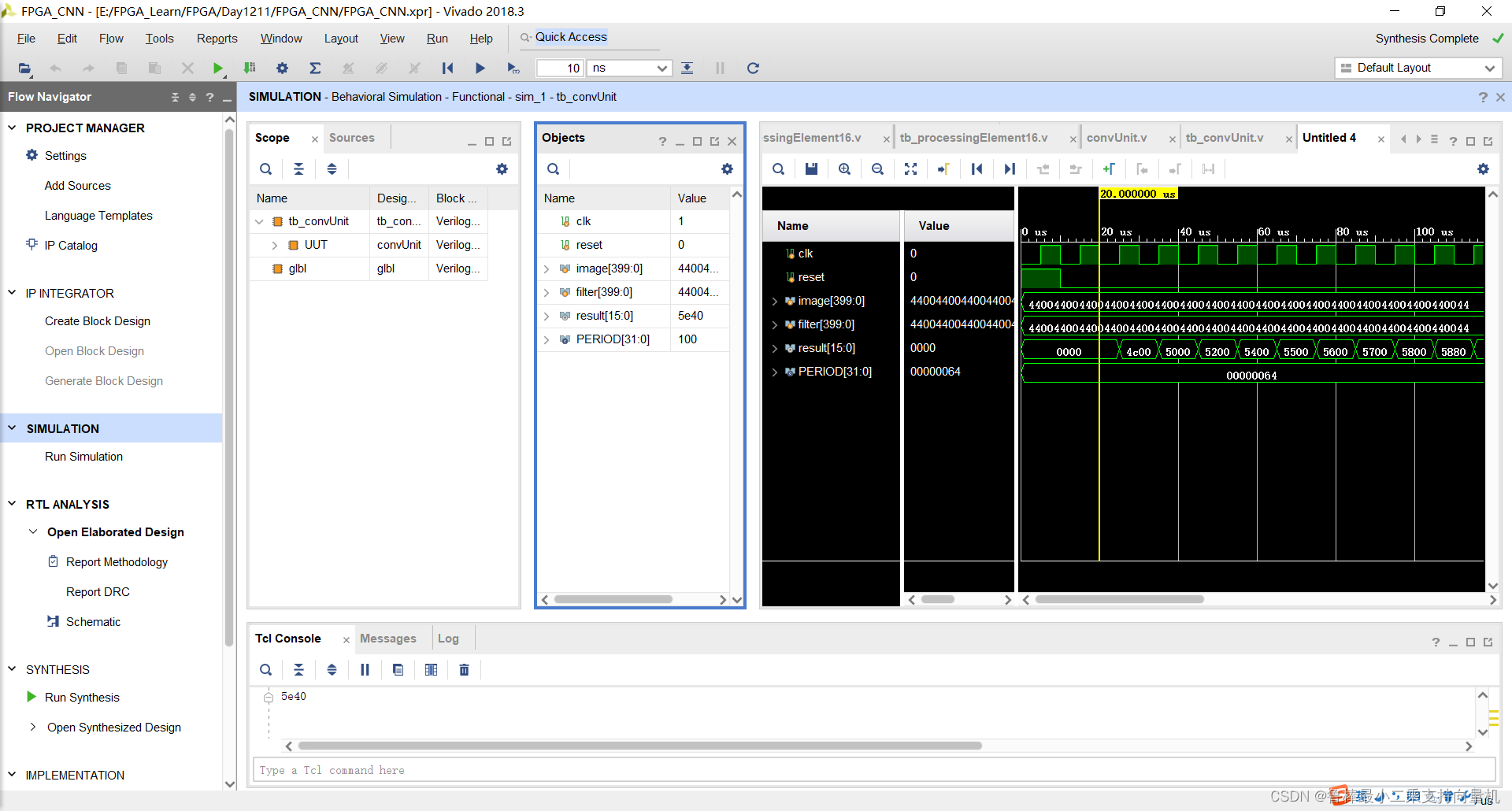
仿真波形,如图:
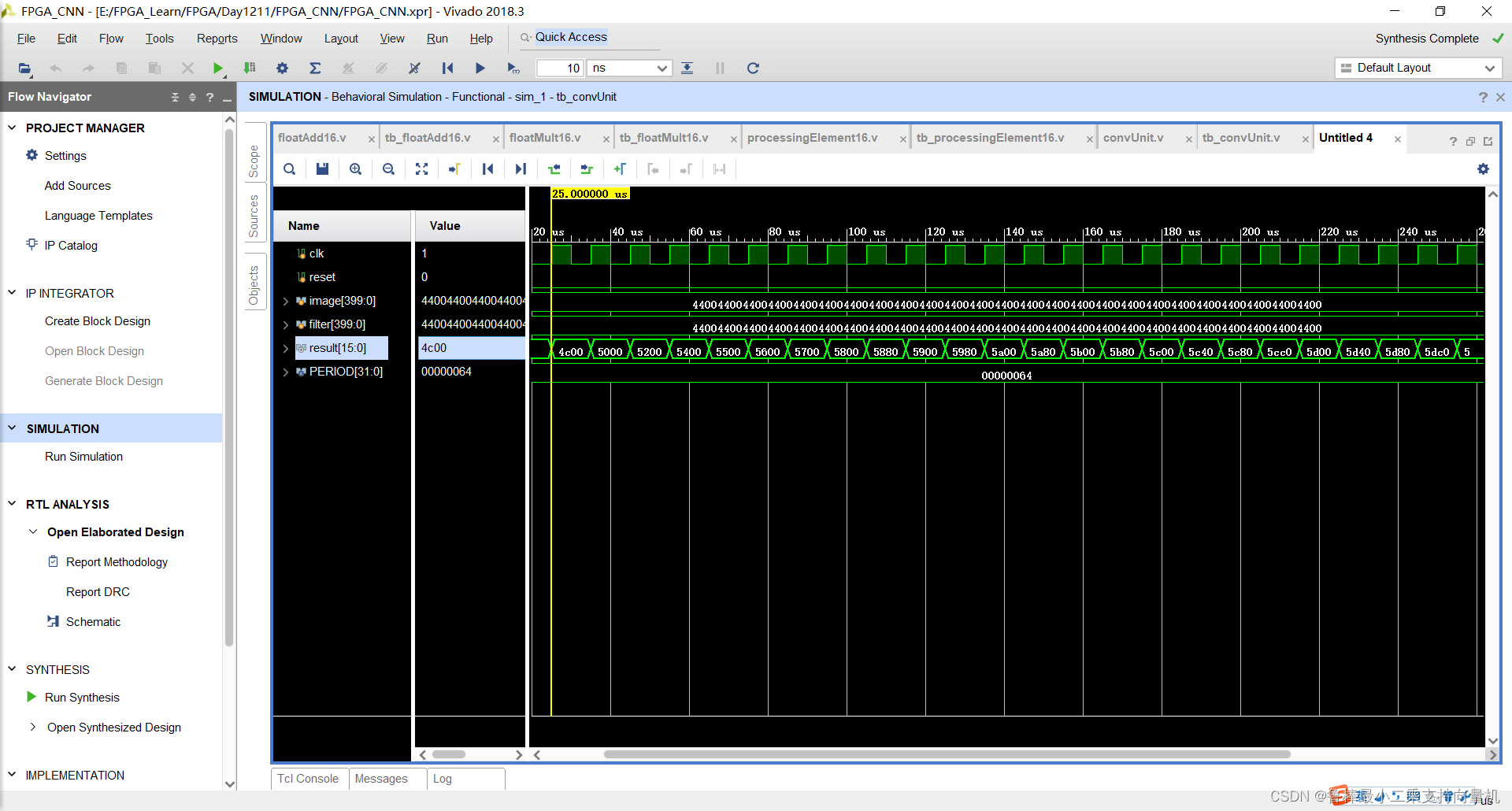
创建convLayerSingle工程文件,如图:
双击打开,输入如下代码:
如图所示:
继续创建RFselector文件:
双击打开,输入如下代码:
如图所示:
将convLayerSingle设置为顶层:
关闭上次的分析文件:
对设计进行分析,操作如图:
分析后的设计,Vivado自动生成原理图,如图:
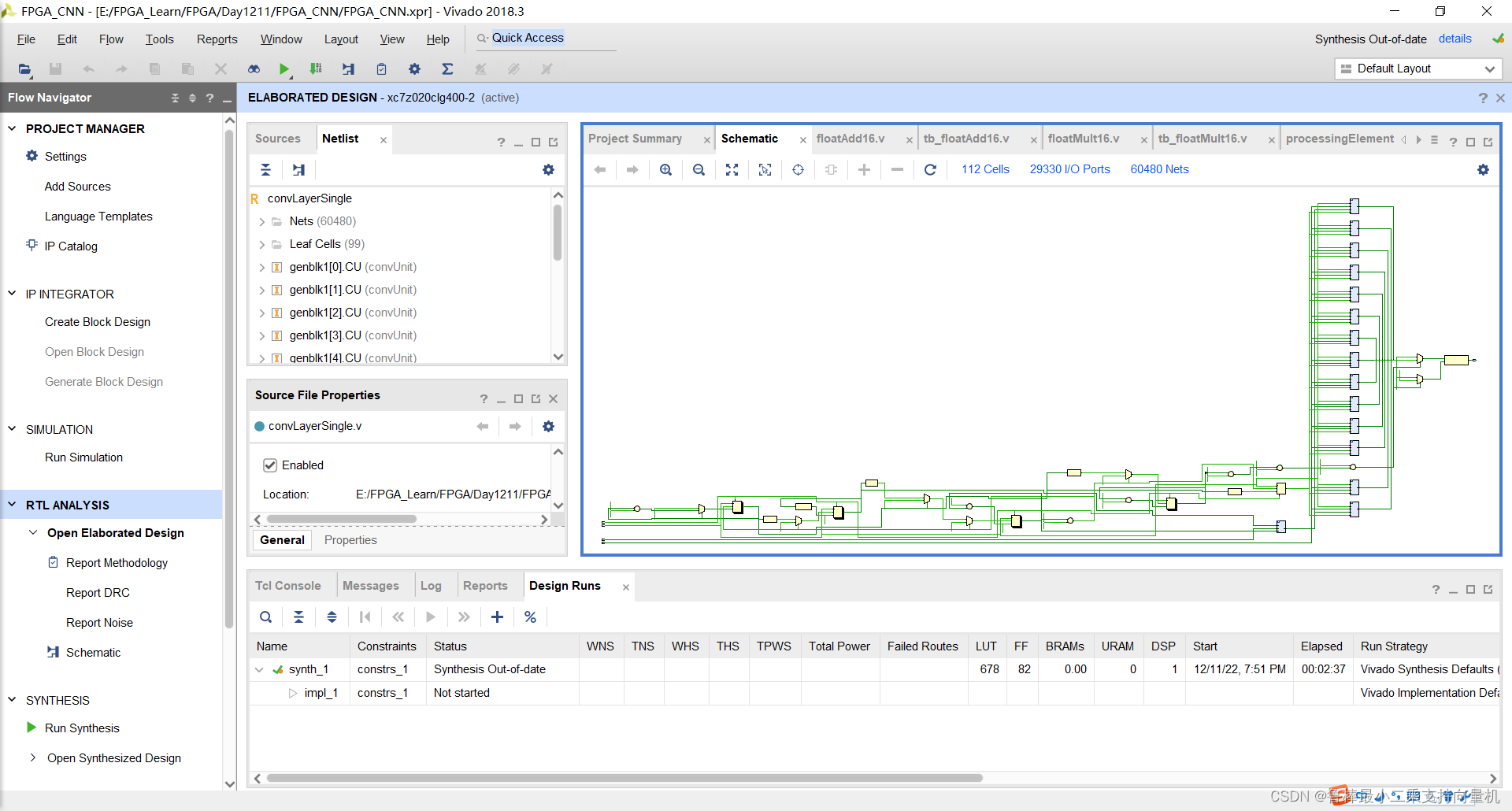
对设计进行综合,操作如图:

创建TestBench,文件名为tb_convLayerSingle,如图所示:
双击打开,输入激励代码:
如图所示:
将tb_convLayerSingle设置为顶层:
开始进行仿真,操作如下:
开始仿真,如图:

仿真波形如图所示:

创建convLayerMulti文件,如图:
双击打开,输入如下代码:
如图所示:
将convLayerMulti设置为顶层:
关闭上次的分析文件:
对设计进行分析,操作如图:
分析后的设计,Vivado自动生成原理图,如图:
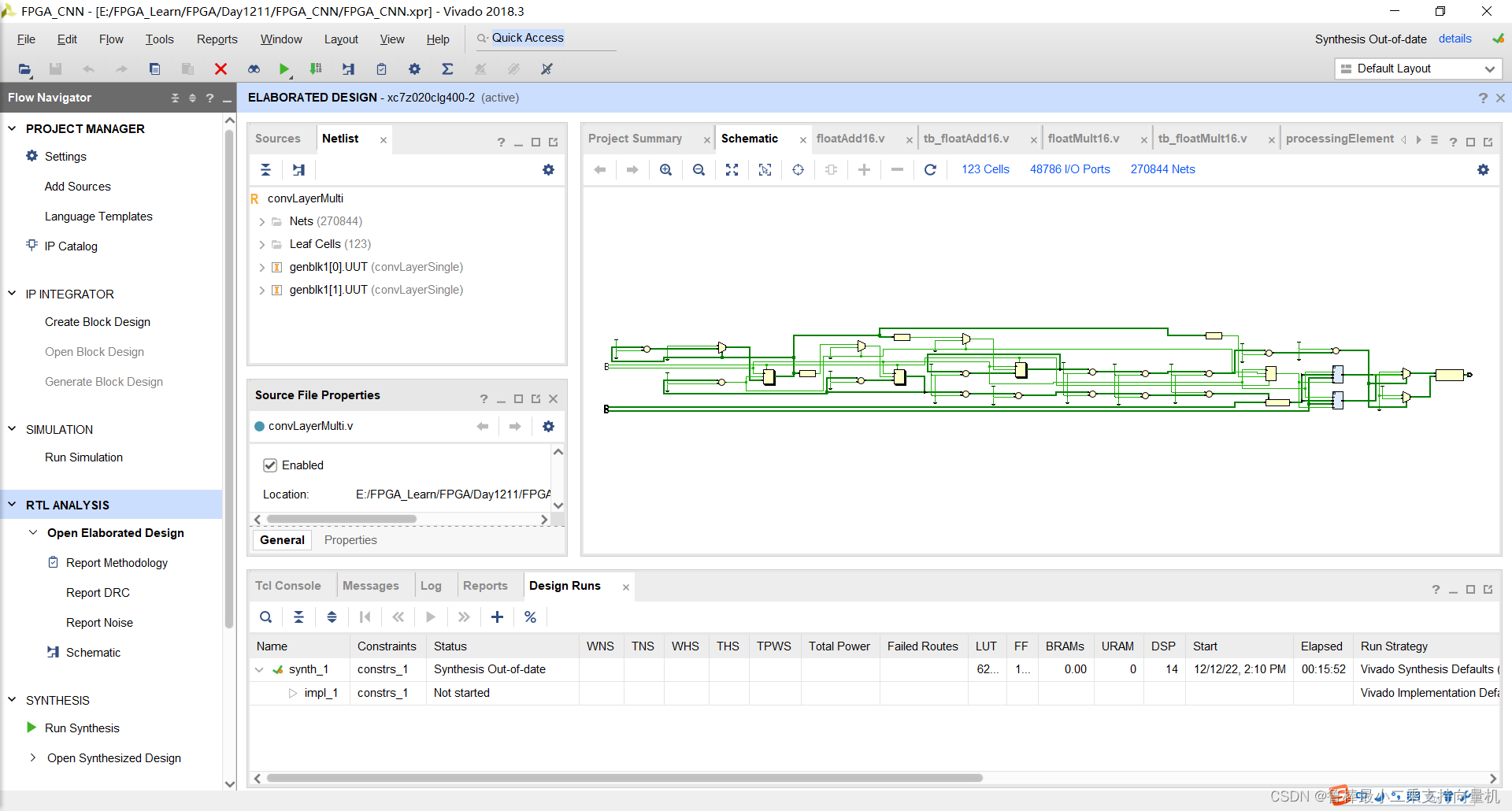
对设计进行综合,操作如图:
创建TestBench,操作如图所示:
双击打开,输入激励代码:
如图所示:
开始进行仿真,操作如下:

开始仿真,如图:
创建integrationConv文件,如图:
双击打开,输入如下代码:
如图所示:
将integrationConv设置为顶层:

关闭上次的分析文件:
对设计进行分析,操作如图:
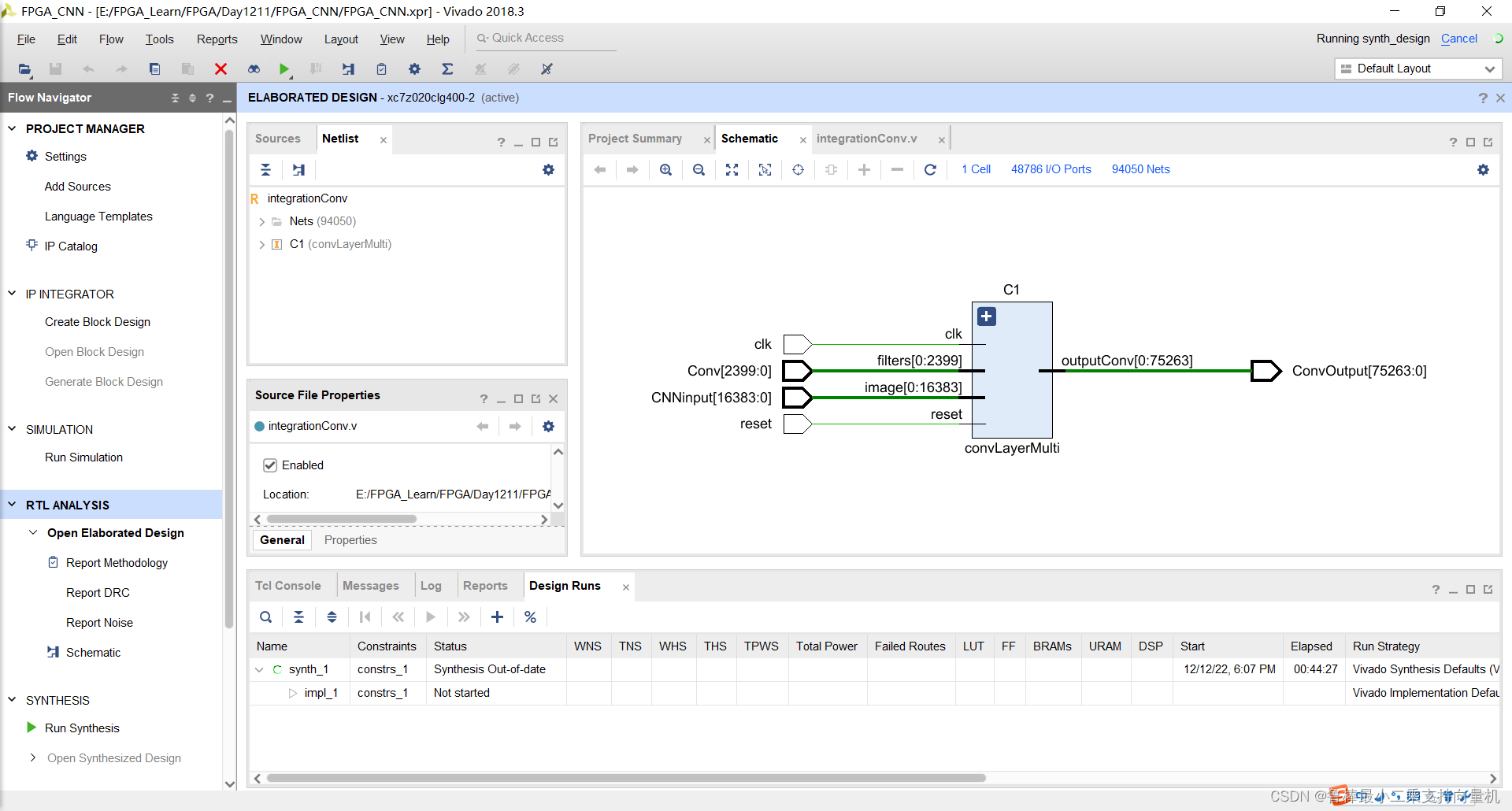
分析后的设计,Vivado自动生成原理图,如图:
对设计进行综合,操作如图:

希望本文对大家有帮助,上文若有不妥之处,欢迎指正
分享决定高度,学习拉开差距
以上就是本篇文章【一起学习用Verilog在FPGA上实现CNN----(二)卷积层设计】的全部内容了,欢迎阅览 ! 文章地址:http://www.razcy.com/news/3191.html 资讯 企业新闻 行情 企业黄页 同类资讯 首页 网站地图 返回首页 月落星辰移动站 http://m.razcy.com/ , 查看更多 点击拨打:
点击拨打: